一、前言
mergecap为wireshark下的配套命令,是wireshark安装时附带的可选工具之一,mergecap用于合并多个包文件。
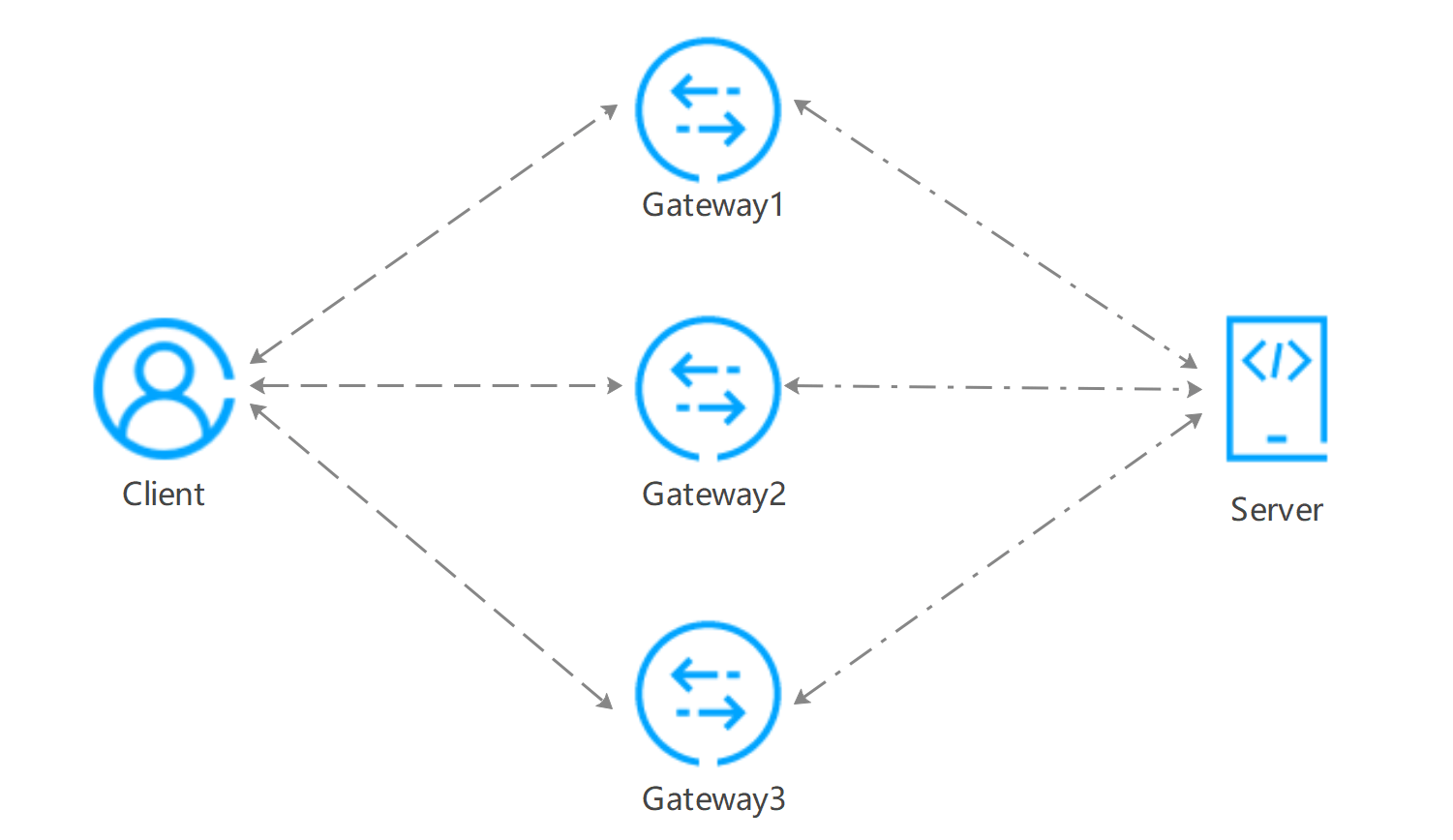
在日常网络抓包排障中,网关、集群可能是由多台机器节点组成的一个整体,或者出方向和入方向所经过的节点不一致,此时抓包会产生不止一个包文件,每个包文件为经过其中一个组成节点的部分,而要完整分析整条流,则需要把这些包文件合并为一个包文件,才是完整的交互报文,因此,mergecap合并包无非以下几种场景:
-
抓包来自网关不同的节点(与网络架构有关),需合并为一个才是完整的交互;
-
抓包时设置相关参数(比如每五分钟保存一次、或满1G则保存一次)自动切割为了多个文件,分析时需合并为一个,防止交互流量(比如TCP流)分布在多个包文件不利于分析。
本文将详细阐述mergecap的用法和使用案例。
二、安装
Linux
| 发行版 | 安装命令 |
|---|---|
| Archlinux | pacman -Sy wireshark-cli |
| Centos/Redhat | yum install -y wireshark |
| Debian/Ubuntu | apt install -y wireshark |
| Gentoo | emerge –ask wireshark |
Windows
安装wireshark后,mergecap默认在wireshark安装路径:
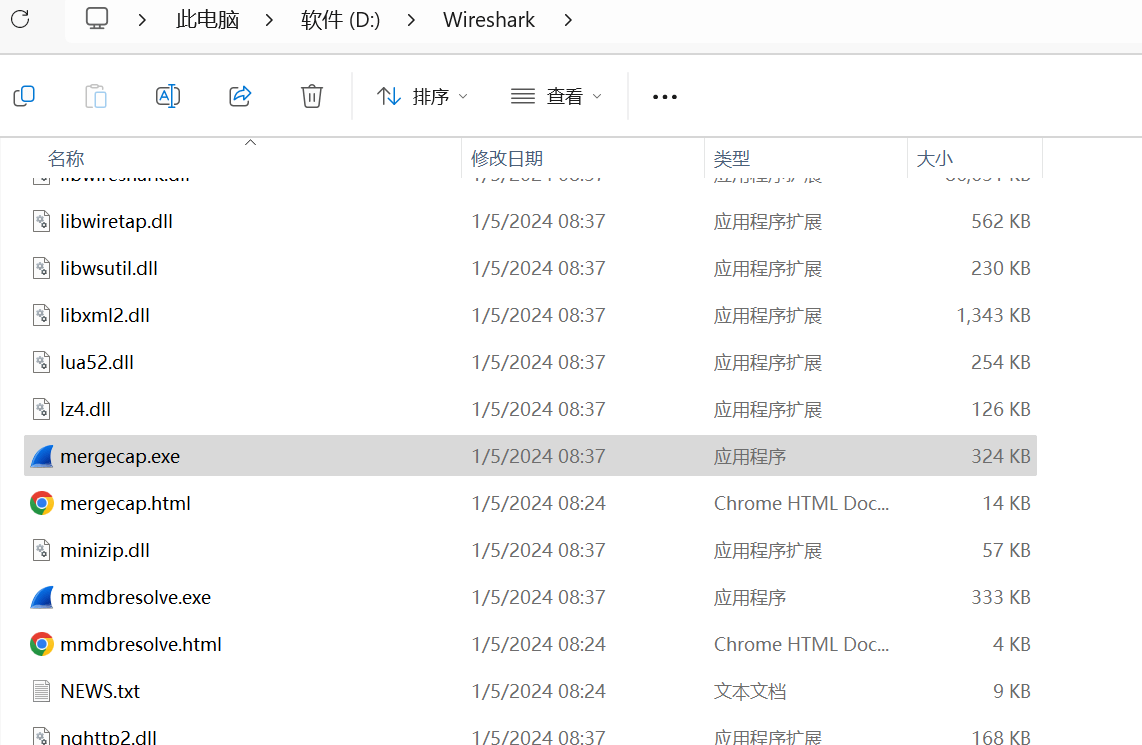
其它配套命令也都在这个路径下:
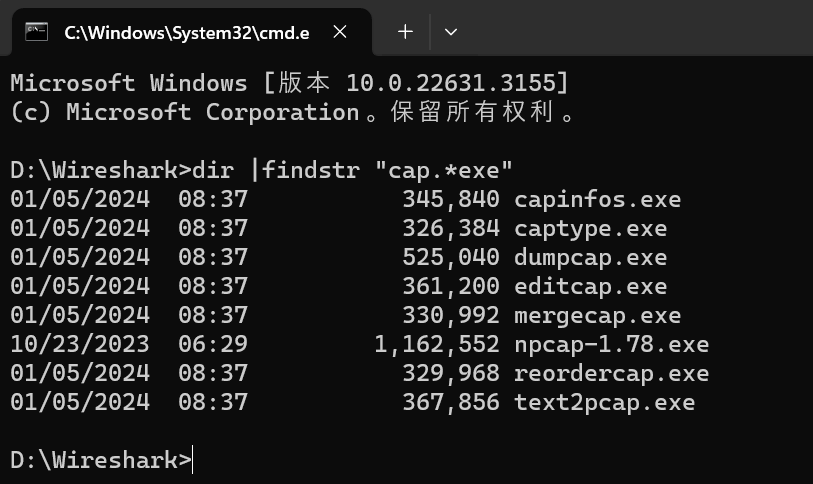
添加路径到环境变量还是直接在路径下使用,可自行选择。
MacOS
前提:需要安装homebrew
使用homebrew安装wireshark,默认会将mergecap安装上去:
brew install wireshark
brew install wireshark-chmodbpf三、用法案例分析
1.合并多个包(-w)
比如上面这三个pcap包文件,一条完整的TCP流被分割为了三个文件:
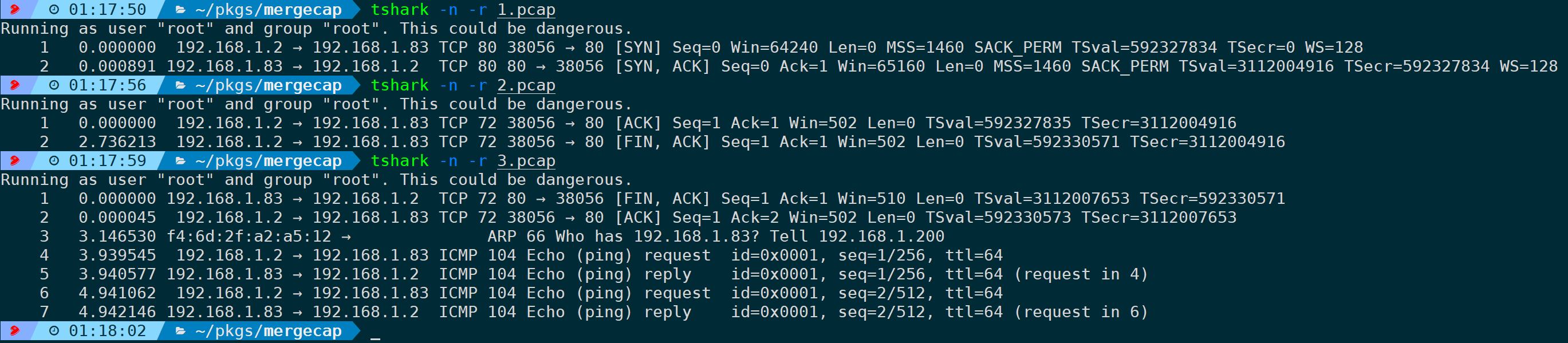
- 1.pcap为第一次和第二次TCP握手的两个包:SYN和SYN,ACK;
- 2.pcap为第三次握手:ACK + 开始挥手:FIN,ACK 共两个包;
- 3.pcap为剩余的完整挥手(FIN,ACK和ACK)以及一次ARP和两次ICMP Request和Reply。
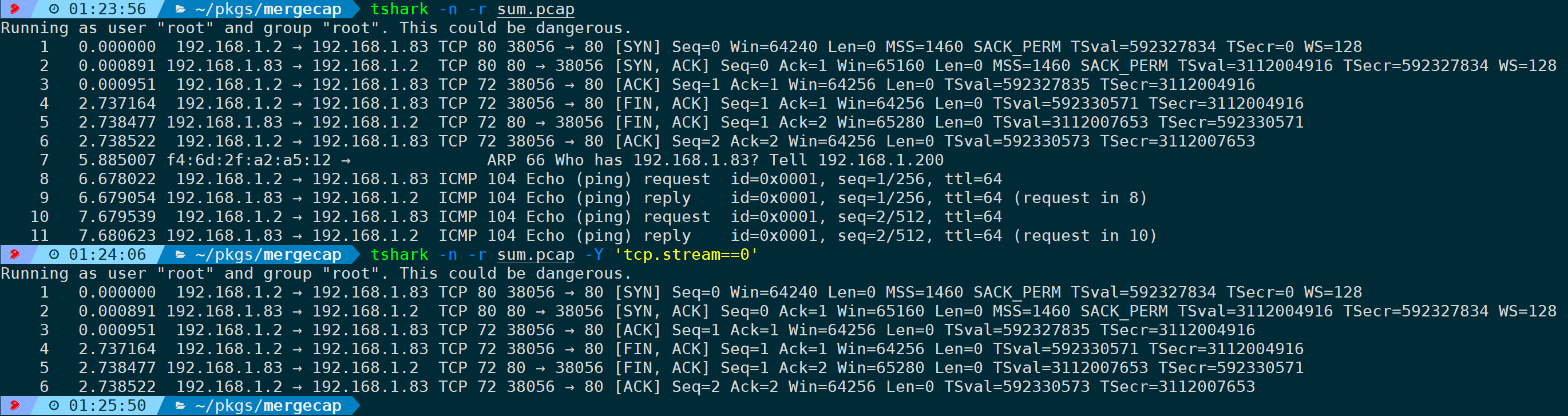
此时我们要分析TCP流的话,单独分析某个包都不是完整TCP Stream,加大分析难度,此时需要把这三个包合并为一个包;-w参数指定输出的包名,目前已知当前目录下有三个包文件:1.pcap、2.pcap、3.pcap,合并为sum.pcap,可以是:
mergecap -w sum.pcap 1.pcap 2.pcap 3.pcap很明显合并后更利于分析完整的TCP流:
同时,支持扩展写法:
mergecap -w sum.pcap *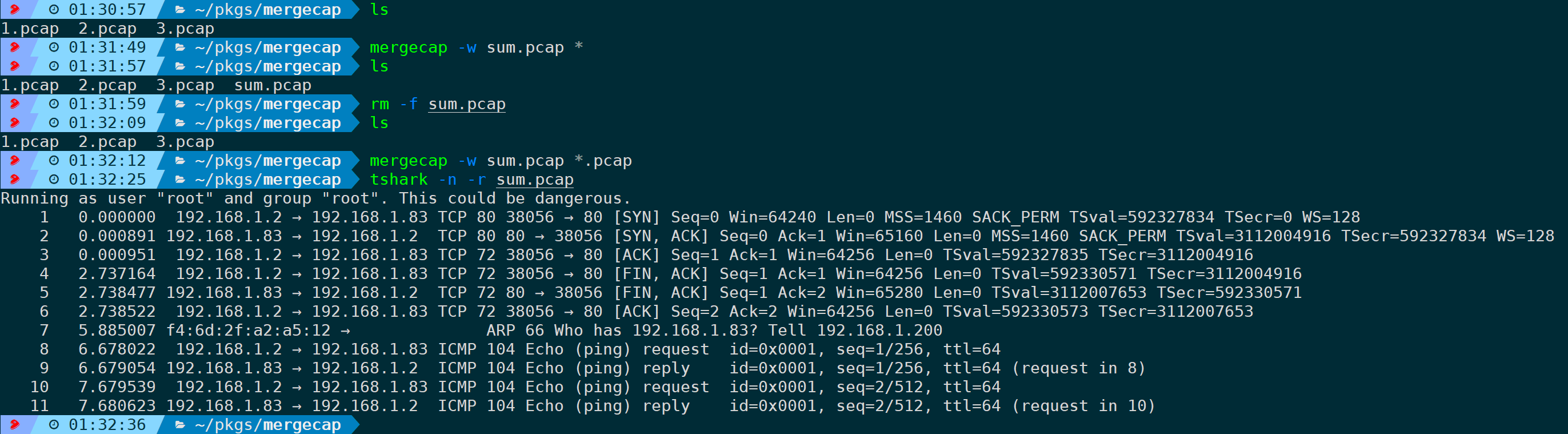
- 写为*则将当前目录下所有文件进行合并;
- 写为*.pcap,则将当前目录所有.pcap结尾的文件进行合并。
如果不需要合并为文件,只是输出给STDOUT处理,比如管道给tshark、tcpdump等进行处理分析,那么-w也支持使用标准参数"–",比如合并后输出到STDOUT,之后管道给tshark进行读取:
mergecap -w - * | tshark -n -r -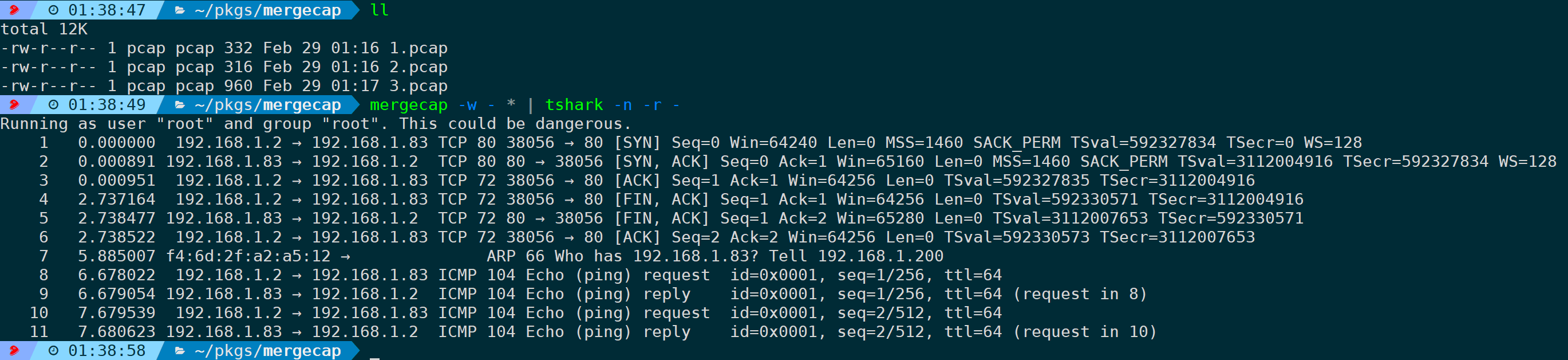
同理,也能递交给tcpdump进行处理,甚至在上面做一些过滤,比如过滤第一条TCP流:
mergecap -w - 1.pcap 2.pcap 3.pcap | tcpdump -n -r - 'tcp[12:4] & 0x0f000000 == 0'
2.按照包顺序合并,而非时间戳顺序(-a)
使用-w参数默认情况下,默认会按照时间戳顺序进行帧合并,如果你不想按照时间顺序合并,而是根据入参的文件绝对顺序进行排列,则可以加上-a参数:
mergecap -a -w sum.pcap 3.pcap 1.pcap 2.pcap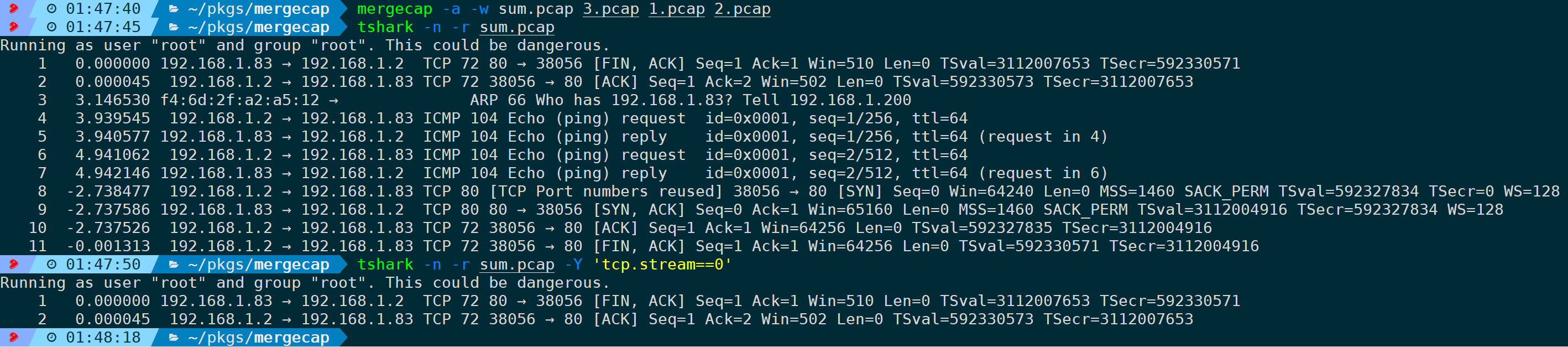
这里作为演示,特意将3、1、2三个包的入参顺序打乱,合并为sum.pcap,可以看到sum.pcap的包序严格按照入参的包文件顺序进行合并,此时再进行TCP流分析,读取不到完整的流。
即使使用wireshark打开,它也是不完整的:
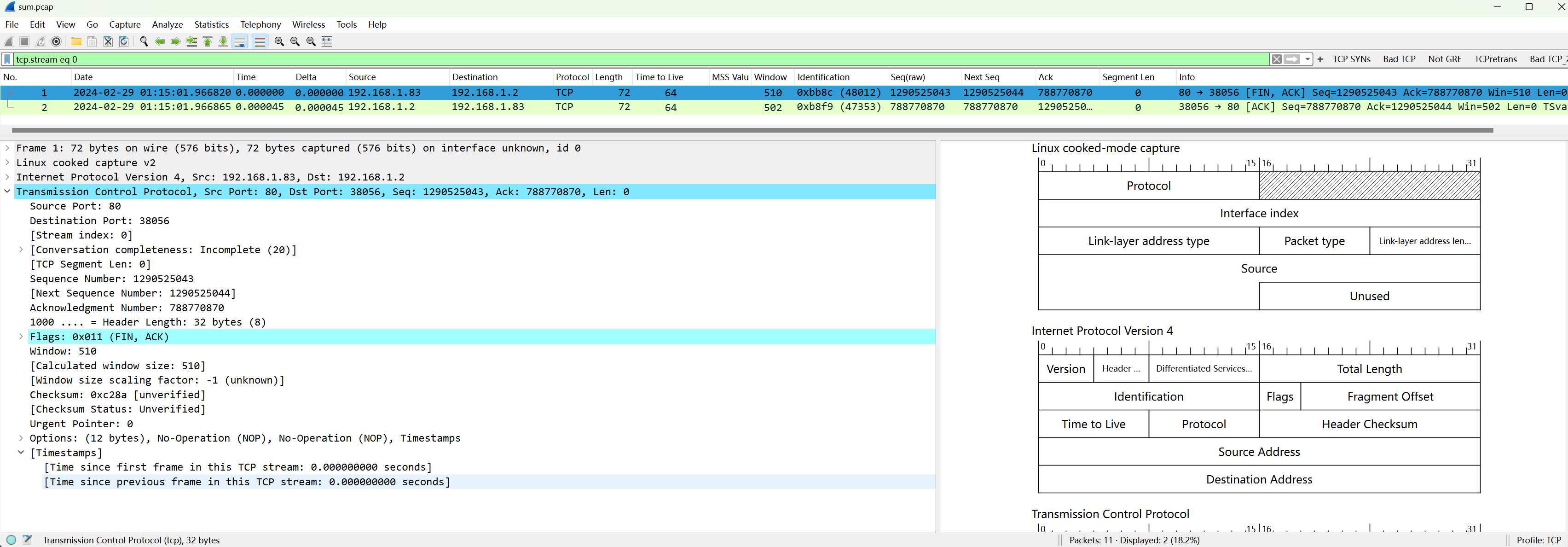
这类合并场景一般是由于在不同节点抓的多个包,时间是不一致的,如果不加-a参数,默认按照时间顺序合并,包也是错乱的,而加上-a则严格按照入参的包文件先后顺序进行合并,此选项不常用也不建议使用,除非你知道自己在做什么。
3.指定截断长度进行合并(-s)
不加此参数默认情况下,以单个帧为维度,帧原始是什么,合并后帧还是什么,原封不动进行合并。-s参数允许合并时把每个包进行截断再合并,比如只取帧的前60字节进行合并,这样二次处理也可以大大缩小包文件大小,把对排障没有帮助的内容截断剔除掉。
比如下面这个例子,一条完整的HTTP流被分割为了两个包文件,http-1.pcap和http-2.pcap:

如果你并不关心七层(HTTP)是什么表现,只需要分析TCP本身是否存在异常,那么合并时可以截断为60字节:
mergecap -s 60 -w sum.pcap http-1.pcap http-2.pcap

可以看到HTTP层被截断了,但TCP层依然正常显示,TCP头部没有缺少任何字段。
1)为什么是60字节而不是54字节?
默认情况下,54字节的情况为:14(以太网头部)+ 20(IPv4 头部)+ 20(TCP 头部)= 54字节:
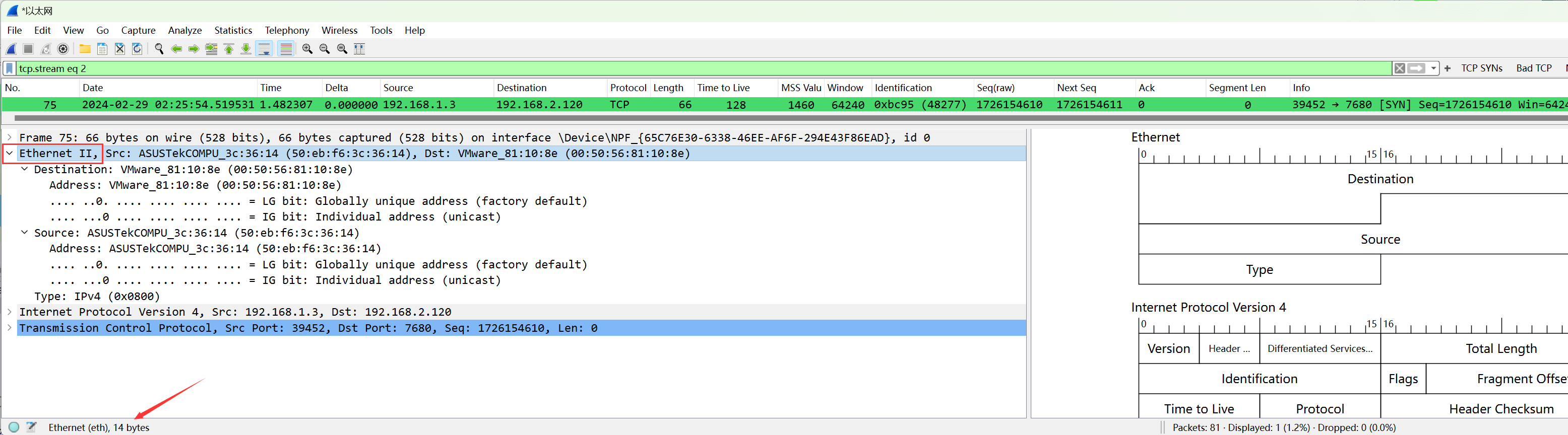
在Linux上抓包,并且抓包接口指定为-i any,即抓取所有接口,此时数据链路层可能不再显示为以太网,而是Linux cooked capture v2(SLL),这是Linux上的伪协议,因为并不是一台机器上的所有接口都具有相同的链路层头部,参考wireshark官网说明。
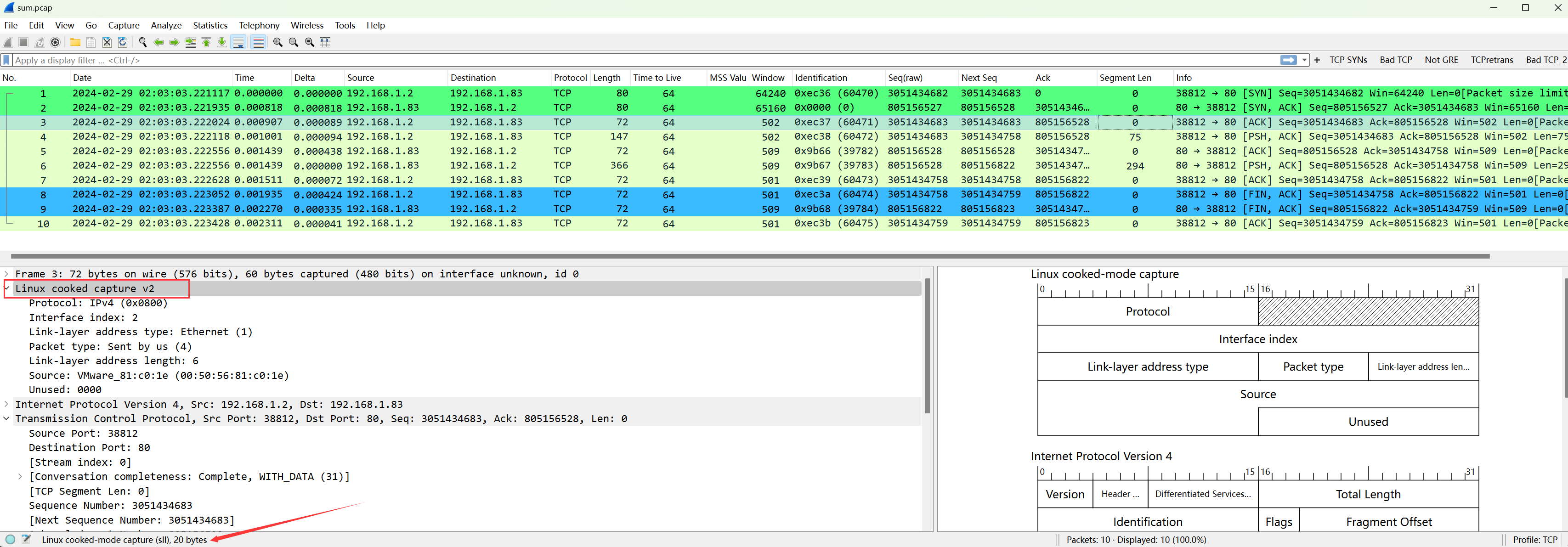
这个头部至少占用20字节,比以太网头部多出6字节:
2)Linux cooked capture(SLL)包结构
Linux cooked capture v2版本包结构为:
+---------------------------+
| Protocol type |
| (2 Octets) |
+---------------------------+
| Reserved (MBZ) |
| (2 Octets) |
+---------------------------+
| Interface index |
| (4 Octets) |
+---------------------------+
| ARPHRD_ type |
| (2 Octets) |
+---------------------------+
| Packet type |
| (1 Octet) |
+---------------------------+
| Link-layer address length |
| (1 Octets) |
+---------------------------+
| Link-layer address |
| (8 Octets) |
+---------------------------+
| Payload |
. .v1版本则为:
+---------------------------+
| Packet type |
| (2 Octets) |
+---------------------------+
| ARPHRD_ type |
| (2 Octets) |
+---------------------------+
| Link-layer address length |
| (2 Octets) |
+---------------------------+
| Link-layer address |
| (8 Octets) |
+---------------------------+
| Protocol type |
| (2 Octets) |
+---------------------------+
| Payload |
. .所以到一直到TCP头部这里总字节为:20(数据链路层头部)+ 20(IPv4 头部)+ 20(TCP 头部)= 60字节;
如果你抓包时并没有使用-i any参数来指定所有接口,那么指定54字节截取头部是完全没问题的,-s 60只是为了保险起见;
4.设置合并后的保存格式或进行格式转换(-F)
默认情况下,输出格式为pcapng,为什么保存为pcap后缀也可以正常打开数据?
mergecap会自动检测文件的格式,并正确解析和显示数据包,即使将pcapng文件保存为pcap后缀,这些工具仍然可以正确识别和打开它,而且pcapng是pcap的升级版本,pcapng具备更好的细节展示和性能改进,因此优先推荐pcapng格式。
1)格式列表
其它格式按需进行保存,-F不接任何参数可以列出支持的保存格式:
mergecap -F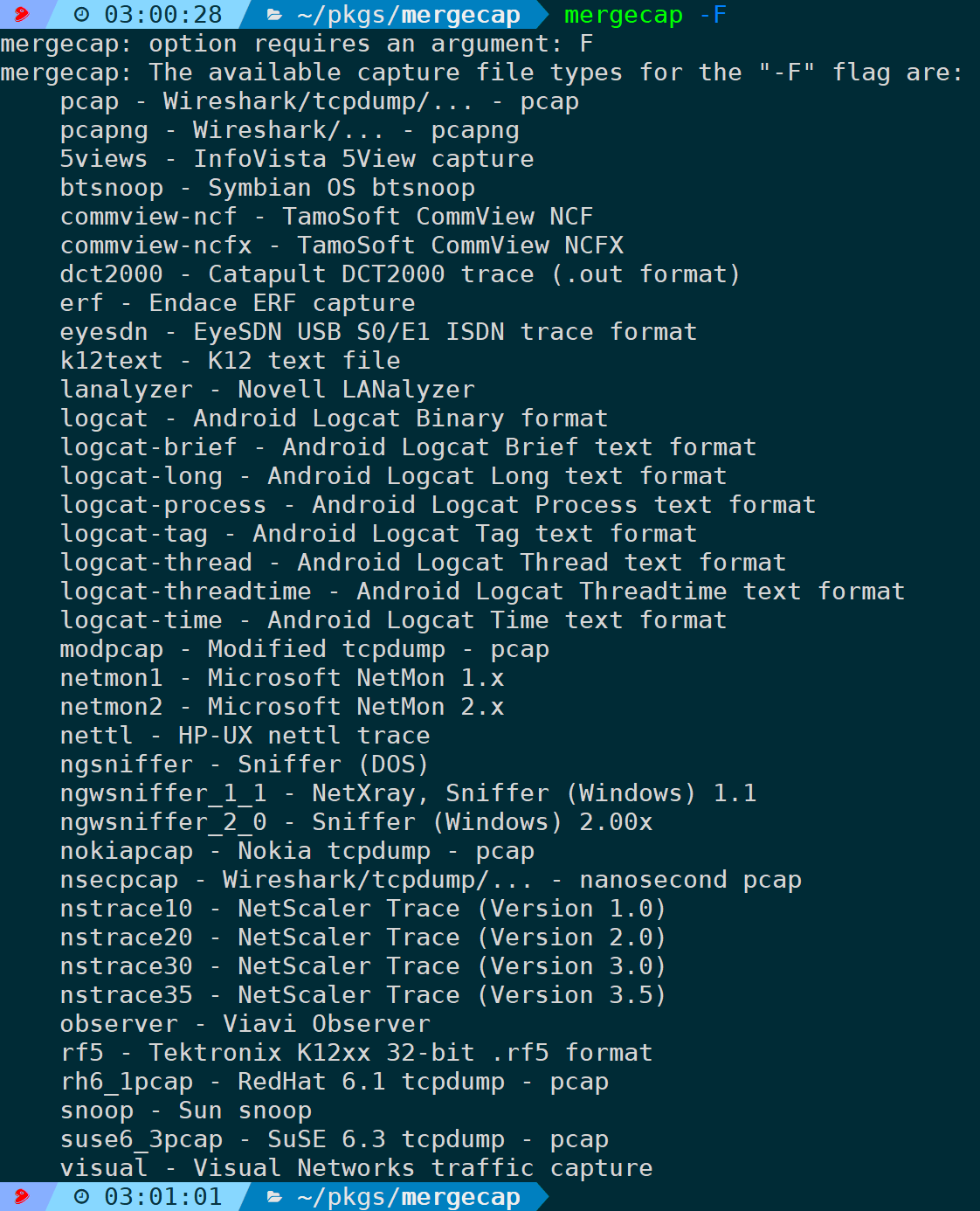
注意,除了pcap、pcapng不用单独指定-F选项外,其它格式都需要指定,如果只是修改格式后缀而不通过-F来指定对应格式,实际还是按照pcapng格式来保存,结果就是无法正确读取相应的格式,因此你也可以理解为此选项可以将某个格式的抓包文件转换为其它格式。
没有现成环境,以pcapng格式为例,依然设置截断长度为60:
mergecap -F pcapng -s 60 -w sum.pcapng http-*.pcap
2)格式转换
同时支持格式转换,比如pcapng转换为pcap:
mergecap -F pcap -w sum.pcap sum.pcapng
转换成其它格式也是同理。
四、总结
到此为止,已经全面探讨了 mergecap 的用法案例,详细介绍了如何合并多个包文件以及不同格式之间的转换,同时具体分析了如何截断保存抓包文件才能缩减包大小和减轻工作负担,顺便穿插了Linux cooked capture的概念。
同时,在文章中,首先介绍了 mergecap 的使用场景,然后通过实际案例展示了如何在不同场景下使用该工具。通过阅读本文,读者应该能够熟练掌握 mergecap 的使用技巧并在实际工作中灵活运用,从而提高工作效率和数据包分析的准确性。