
一、前言
tshark作为Wireshark的配套子命令,在CLI场景下能胜任Wireshark绝大部分功能,对于需要批量处理、筛选过滤、导出、统计分析、定制化输出等能力。
当然,tshark同时具备抓包和分析包的能力,简单理解为tshark是wireshark的CLI版本,但Linux端抓包基本上业界都会使用tcpdump,并且它基本能覆盖抓包的所有场景,如果想要了解tcpdump的用法,可以参照笔者总结的这篇文章。
因此本文将不再讲述tshark的抓包用法,而着重讲述tshark配合诸如grep、sed、awk等文本处理工具如何分析过滤报文、批量处理报文等,拿到我们想要的任何报文内容,这些都是图形化wireshark所做不到的,也是CLI与生俱来的优势。

二、各个发行版安装方式
tshark是wireshark的子命令,默认情况下会携带,gentoo是另外,需要使用USE标记,以下是各发行版的安装命令:
| 发行版 | 安装命令 |
|---|---|
| CentOS | yum install wireshark -y |
| Debian/Ubuntu | apt install wireshark -y |
| Archlinux | pacman -Syu wireshark |
| Gentoo | USE="tshark" emerge –ask wireshark |
如果是Windows客户端,安装wireshark即可,tshark默认会被安装到wireshark所在路径。
三、用法案例及参数说明
1.读取报文文件不做任何过滤(-r|–read-file)
使用-r|–read-file参数读取抓包文件:
tshark -r <filename>
会简略的把包文件的报文打印出来,可以看到是一条完整的TCP三次握手与四次挥手的过程。本文着重于如何处理分析已经捕获的报文,因此-r参数在后面的示例中都会被用到。
2.禁止反向解析(-n/-N)
1)禁止一切反向解析(-n)
为了防止IP地址、端口等被反向解析为主机名、端口名时,-n参数较为常用,可以更直观看到交互的五元组信息,而不是别名形态:
tshark -n -r <filename>
2)对传输层端口进行解析(-N t)
区别于-n,-N参数则可以做到精准控制解析哪些层级,格式为:-N <反向解析flag>,flag取值及含义如下:
| flag取值 | 含义 |
|---|---|
| d | 对于DNS包启用解析 |
| m | 启用MAC地址解析 |
| n | 启用网络地址解析 |
| N | 使用外部解析器(例如DNS)进行网络地址解析,n需要被同时启用才有效果 |
| t | 启用传输层端口解析 |
| v | 启用VLAN ID的名称解析 |
tshark -N t -r <filename>
不难看出,80端口前面加上了http协议标识,而37546为随机高端口,没有特殊含义,因此没有解析到任何符合特征的协议。
如果要同时启用多个解析,比如同时启用网络地址解析、传输层端口解析,可以是:
tshark -N n -N t -r <filename>3.解码输出(-d)
格式为:-d <layer type>==<selector>,<decode-as protocol>
也就是wireshark里的“解码为(Decode As)”功能,将特定协议层级,按照手动指定的协议解码输出。
简单理解为,匹配符合条件的包,并将这些包按照指定协议来解析输出一遍。
tshark在默认情况下会根据协议特征和端口标准来自动解码数据包,比如443端口会自动解析为SSL,无需额外指定-d参数,但在某些情况下,特定协议可能有多种变体或扩展,或者端口自定义后并且从协议特征分析有多种协议符合特征,而tshark的自动解码可能只是选择了其中一种,那么手动指定协议解析就派上用场。
执行tshark -d --help 可以列出支持解码的过滤条件及协议:
tshark -d --help|&grep tcp # 过滤TCP相关的过滤器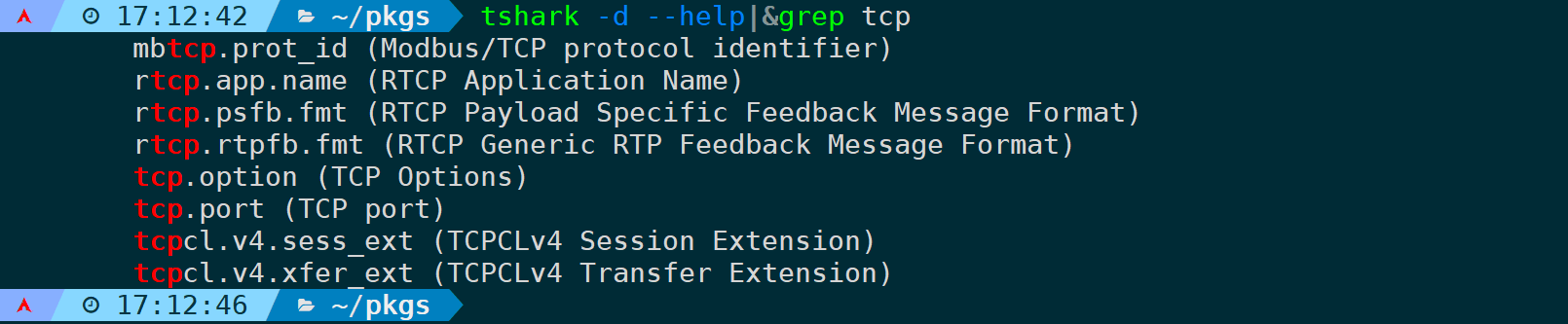
因为tshark对于协议的自动解析能力基本上都能覆盖,手上目前还没有这种需要被手动指定协议来解码的场景,但还是可以做一些功能上的演示。
比如将TCP 80端口解码输出为ssh协议:
tshark -r <filename> -d 'tcp.port==80,ssh'
这会将符合条件的报文,套用ssh协议来分析解码,再输出到控制台上。
但解码前它实际就是一条正常的HTTP stream:

又或者我们将DNS报文分别解码为rtp、quic协议:
tshark -r dns.pcap -d 'udp.port==53,rtp'
tshark -r dns.pcap -d 'udp.port==53,quic'
tshark会将符合特征的报文解码到我们指定的协议,当然这里不能跨协议解析,比如udp.port==80,http将udp端口80的包解码成HTTP协议这是不存在的,http是基于TCP的实现,不在一个协议栈里,无法解码。
上面的解码仅作为用法示例演示,没有任何意义,请注意辨别。
原始报文为DNS,tshark已经自动帮我们解码适配到正确的协议:

4.输出为特定格式(-T)
指定输出格式可以是:ek|fields|json|jsonraw|pdml|ps|psml|tabs|text
比如输出为json格式可以是:
tshark -n -r <filename> -T json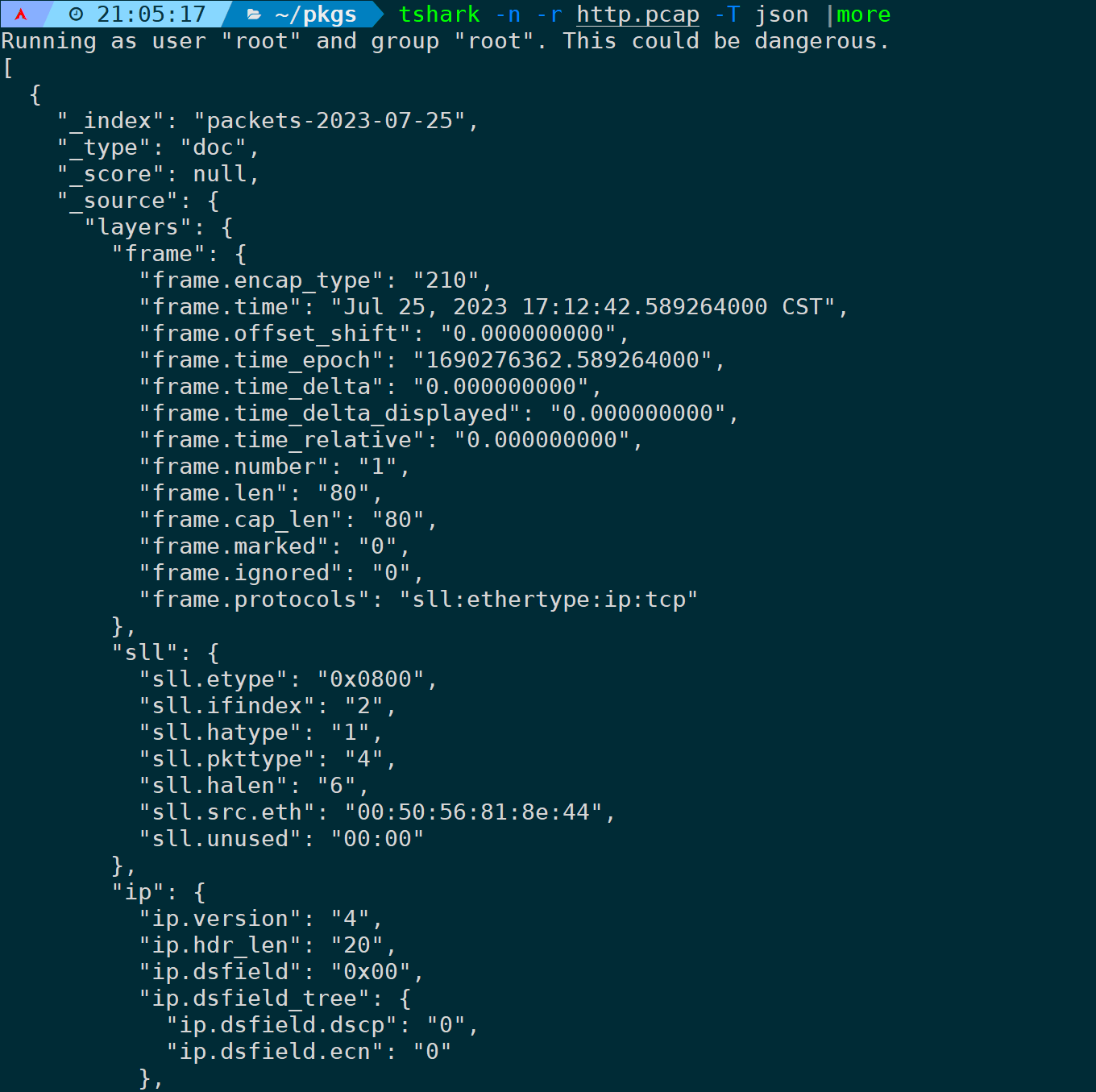
ek格式输出:
tshark -n -r <filename> -T ek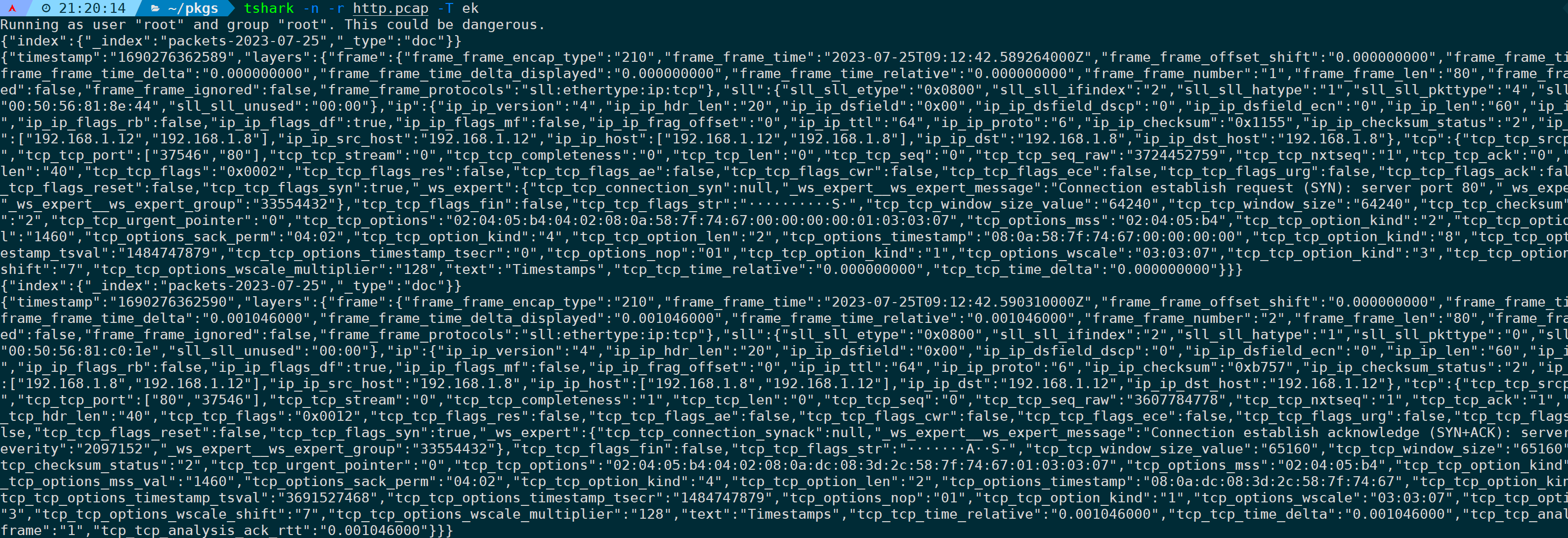
ek格式:Elasticsearch bulk,代表批量写入Elasticsearch的格式。
其中fields格式需要配合-e来使用,不能单独使用,具体用法看下面的-e说明。
5.输出报文指定字段(-e)
-e用来指定报文的某个协议字段,给-T选项处理输出为最终格式。
比如,只需要报文帧数、ip地址、端口、tcp或ip协议的字段并最终输出为fields,可以是:
tshark -n -r <filename> -e 'frame.number' -e 'ip.addr' -e 'tcp.port' -e tcp -T fields
tshark -n -r <filename> -e 'frame.number' -e 'ip.addr' -e 'tcp.port' -e ip -T fields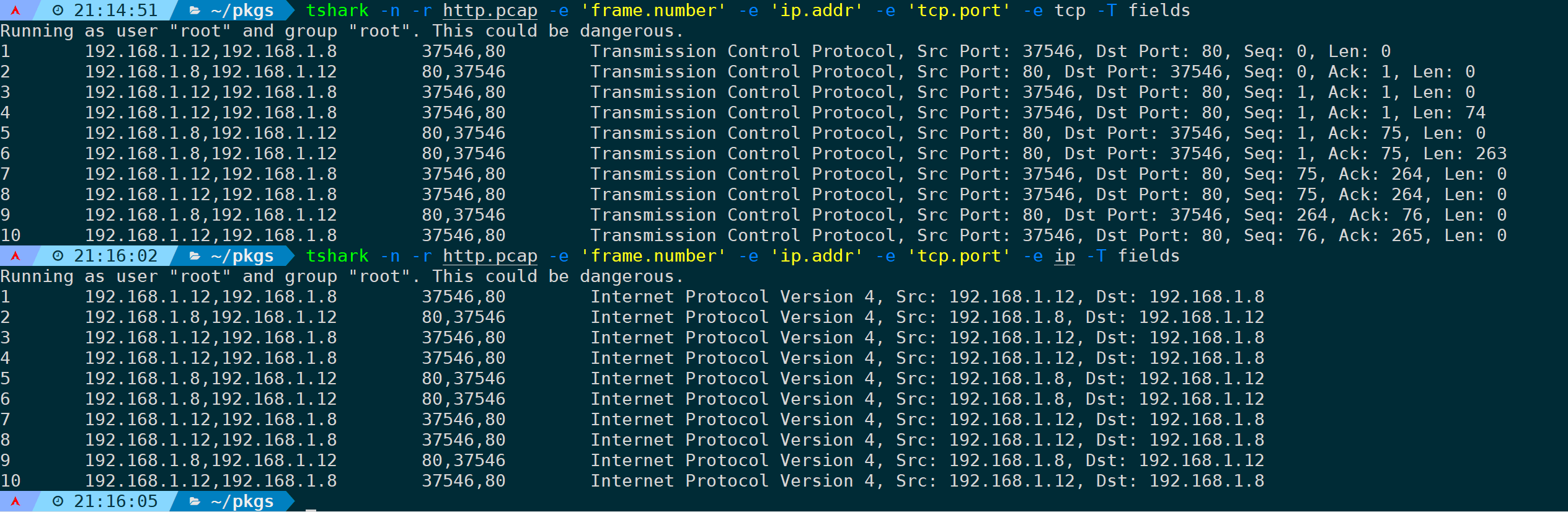
其中,ip.addr、tcp.port都能细分到源ip(ip.src)、目的ip(ip.dst)、tcp源端口(tcp.srcport)、tcp目的端口(tcp.dstport),只要你能想到在wireshark中能作为过滤条件的字段,基本上都可以,用ek格式输出则是:
tshark -n -r <filename> -e 'frame.number' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T ek 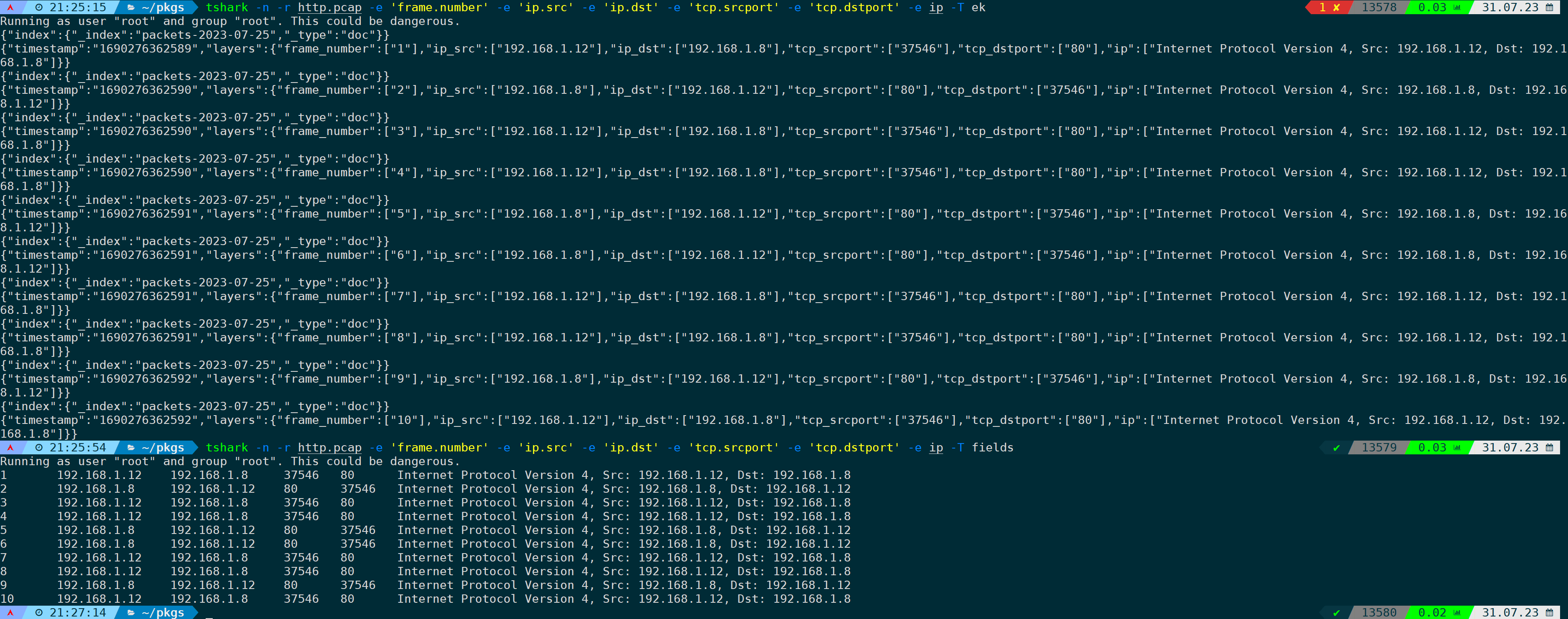
同时,你还可以加入-E header=y参数,来让指定的输出字段,在第一行也对应输出头部字段的含义,之后再通过column命令来对齐格式:
tshark -n -r <filename> -E header=y -e 'frame.number' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields|column -t
6.设置输出的控制字段(-E)
当通过-T参数来输出特定格式时,可以配合-E参数来设置一些选项。
-E能接的参数有:
| 参数选项 | 默认 | 含义 |
|---|---|---|
| bom=y|n | n | 在输出前加上UTF-8字节顺序标记(十六进制ef、bb、bf); |
| header=y|n | n | 打印一个使用-e作为输出第一行的字段名称头部; |
| separator=/t|/s|character | /t | 设置字段分隔符; |
| occurrence=f|l|a | a | 打印每个字段的第一次、最后一次或所有出现的内容; |
| aggregator=,|/s|character | , | 设置用于每个字段内的分割字符。 |
| quote=d|s|n | n | 设置用于环绕字段的引号字符。 |
下面一一举例。
1)bom=y|n
bom(byte-order mark)即字节顺序标记,它是插入到以UTF-8、UTF16或UTF-32编码Unicode文件开头的特殊标记,用来识别Unicode文件的编码类型。对于UTF-8来说,BOM并不是必须的,此选项也不常用,除非有这类需求格式场景。
通过-E bom=y 来启用BOM即可,tshark会在控制字段中插入BOM标记。
比如这条命令,我们指定打印输出某些字段,并且通过bom=y参数插入bom格式:
tshark -n -r <filename> -E bom=y -E header=y -e 'frame.number' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields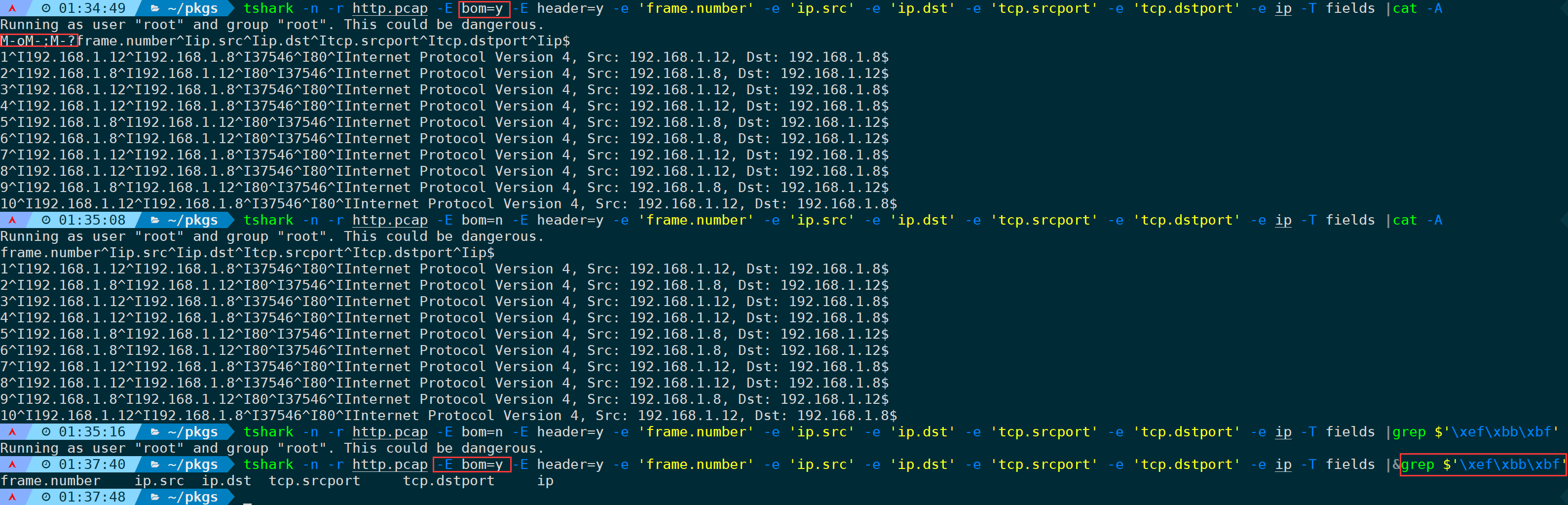
通过对比不难发现,启用bom后,会在输出的开头部分被插入了bom格式,通过grep -r $“’\xef\xbb\xbf’也能匹配到此行。
2)header=y
打印一个使用-e作为输出第一行的字段名称头部,前面已有演示,-e指定的字段,将会在第一行也打印出来这些字段名。
比如指定打印tcp绝对序列号以及五元组信息,可以是:
tshark -n -r <filename> -E header=y -e 'tcp.seq_raw' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields 
3)separator=/t|/s|character
指定字段分隔符,默认为/t,可以指定/s,即单个空格,或者自定义的其它字符。
设置分隔符为两个/t:
tshark -n -r <filename> -E separator=/t/t -e 'tcp.seq_raw' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields设置分隔符为#:
tshark -n -r <filename> -E separator=\# -e 'tcp.seq_raw' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields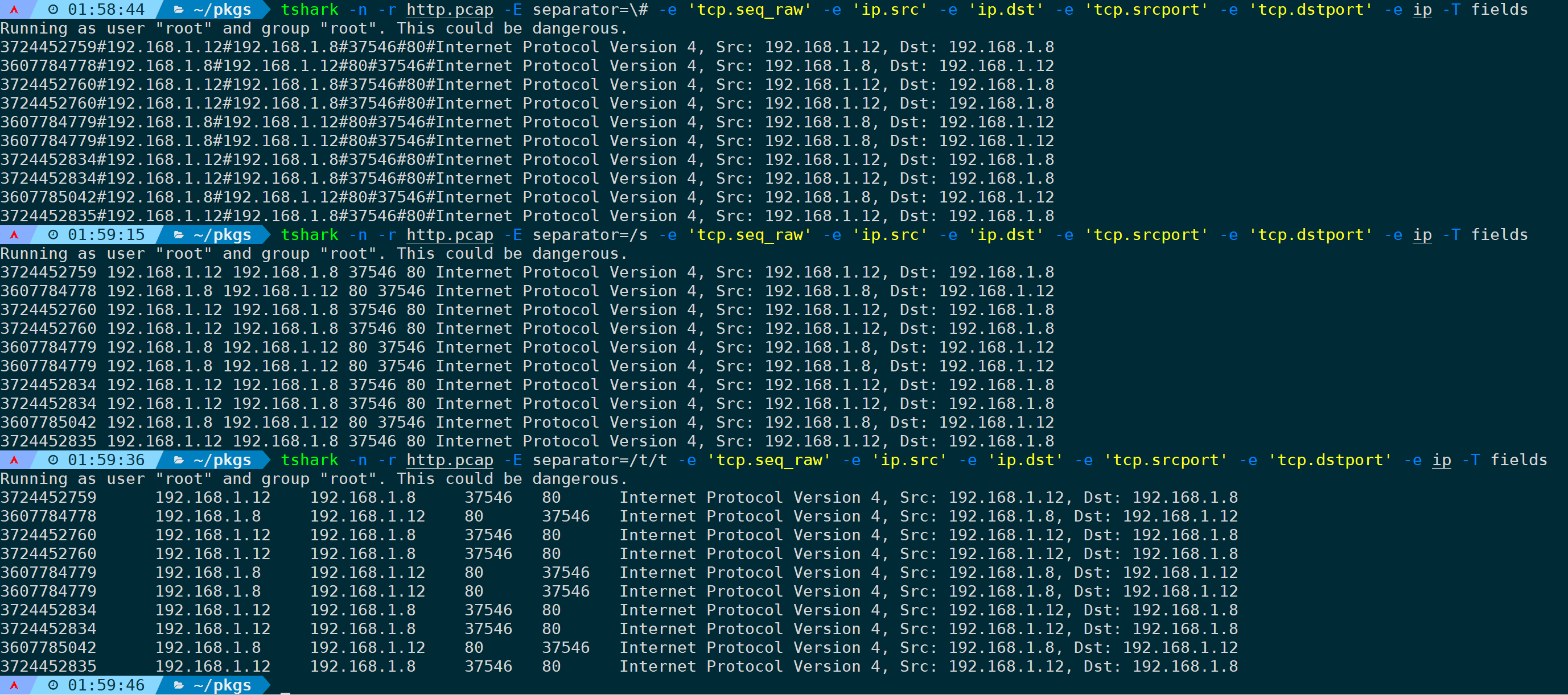
4)occurrence=f|l|a
打印每个字段取值的第一个(f)、最后一个(l),所有(a),当一个字段有多个取值时,默认会打印所有取值,可以通过此参数来指定打印第几个。
比如下面这个包,通过IPIP封装,因此ip有内层和外层:
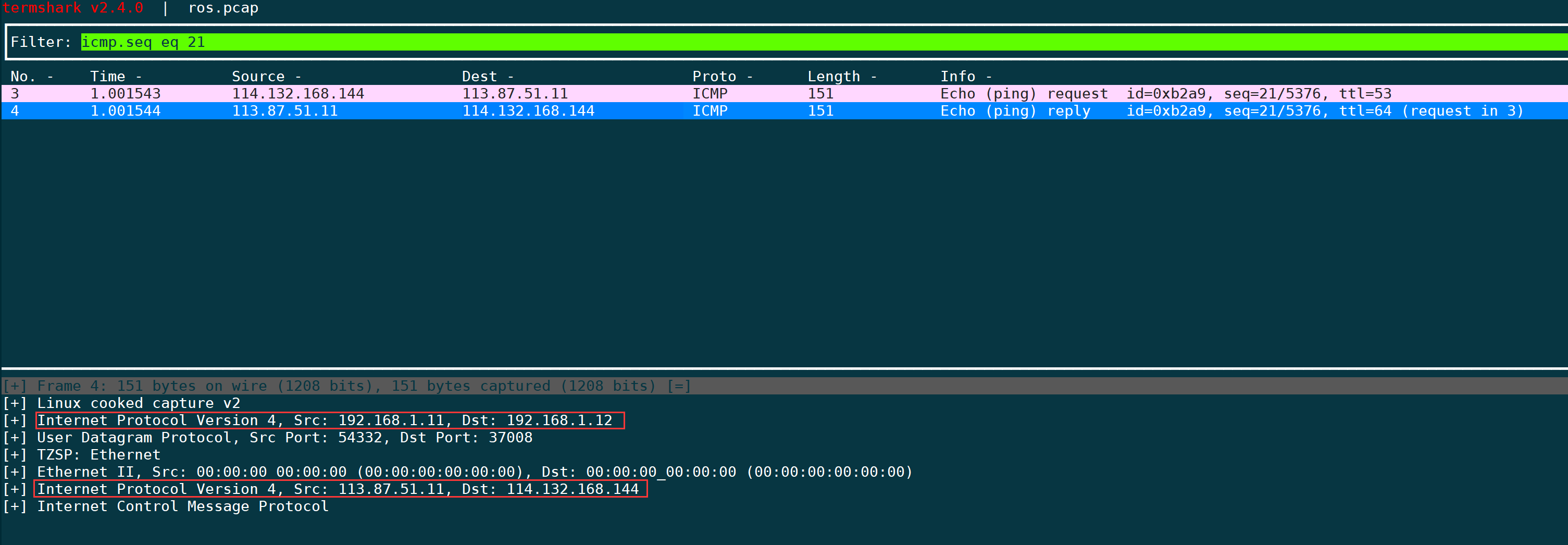
此时我们通过tshark来处理IP字段,occurrence的默认行为是a,即输出字段内所有的内容,会将两个IP都输出出来:
tshark -n -r <filename> -E header=y -Y 'icmp.seq==21' -e 'icmp.seq' -e 'ip.src' -e 'ip.dst' -T fields |column -t
此时我们只想要内层IP,可以通过指定occurrence=l实现:
tshark -n -r <filename> -E header=y -E occurrence=l -Y 'icmp.seq==21' -e 'icmp.seq' -e 'ip.src' -e 'ip.dst' -e ip -T fields |column -t
只想要外层IP,通过指定occurrence=f实现:
tshark -n -r <filename> -E header=y -E occurrence=f -Y 'icmp.seq==21' -e 'icmp.seq' -e 'ip.src' -e 'ip.dst' -e ip -T fields |column -t
5)aggregator=,|/s|character
指定用于字段内的分隔符,当一个字段有多个取值是,默认会用逗号分割,此参数可用于指定分隔符。
比如将IP层的多个IP字段,用分号分割可以是:
tshark -n -r <filename> -E header=y -E aggregator=\; -Y 'icmp.seq>=21' -e 'icmp.seq' -e 'ip.src' -e 'ip.dst' -T fields |column -t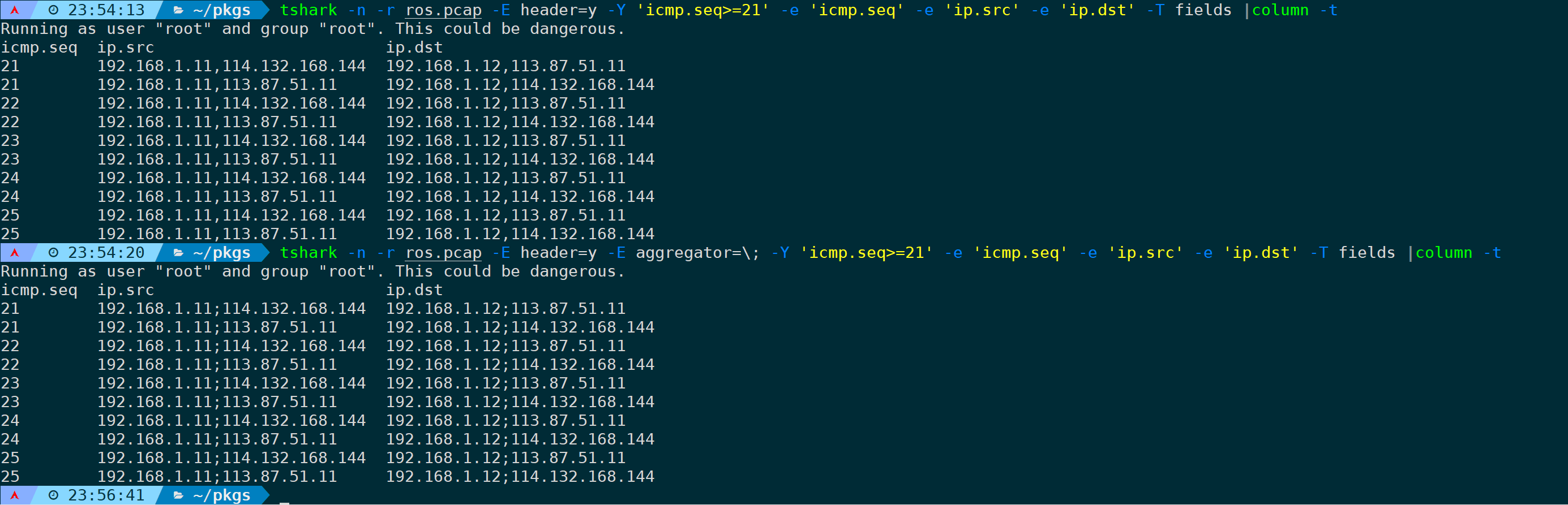
6)quote=d|s|n
设置用于环绕字段的引号字符,d表示double,s表示single,n表示no,默认为n,即不使用引号。当输出的字段需要被引号引起来时,可以通过设置此参数实现。
将每个输出字段用双引号引起来,通过quote=d来实现:
tshark -n -r <filename> -E header=y -E quote=d -e 'tcp.seq_raw' -e 'ip.src' -e 'ip.dst' -e 'tcp.srcport' -e 'tcp.dstport' -e ip -T fields|column -t
quote=s则使用单引号:
tshark -n -r <filename> -E header=y -E quote=s -E occurrence=f -Y 'icmp.seq>=21' -e 'icmp.seq' -e 'ip.src' -e 'ip.dst' -e ip -T fields |column -t
7.二次依赖分析(-2)
指定此参数,tshark会根据上下文报文的依赖关系(tshark称之为two-pass,即进行两次分析),来显示相关报文关联信息,比如:’response in frame #‘、’reply in frame‘、’TCP Port numbers reused‘等字段。
1)端口复用场景(Tcp Port numbers reused)
比如下面这个示例,在wireshark中打开,会显示前后文的依赖关系,比如第2帧提示的端口复用(tcp port numbers reused):
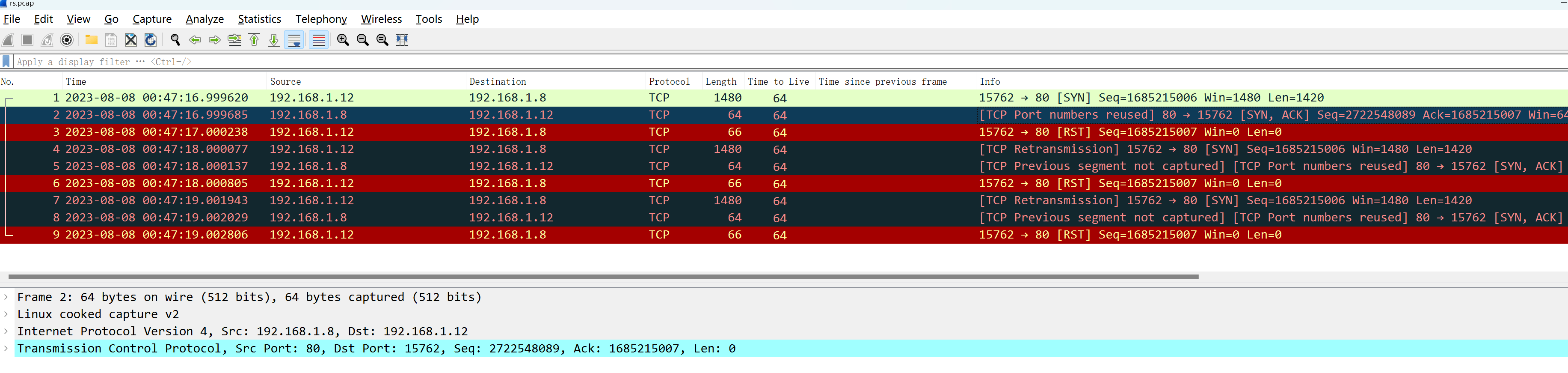
而如果直接使用tshark来看,是没有这个提示信息的:

加上-2参数,让它进行一次完整的前后文分析并将这些字段计算出来,则能正常显示:
tshark -2 -n -r <filename>
2)ICMP REPLY场景(icmp reply #frame)
再比如icmp场景,不进行二次分析的情况下,第一次的icmp request,并不会在结尾显示reply in 2(即reply报文为第二帧)的提示信息:

3)分片重组场景(Reassembled in #frame)
又或者分片场景,ping一个icmp大包,超过mtu后会分片传输,在wireshark打开后显示如下:
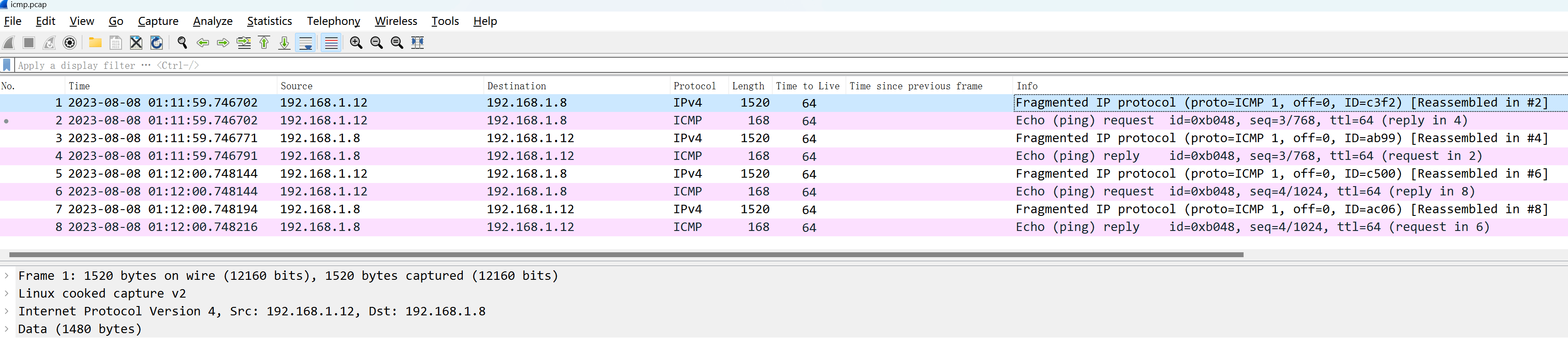
收到的request大包会分成两帧传输,而reply并不需要响应大包,字节数没有超过mtu,因此无需分片。
在tshark中打开则为:

提示有分段,但并没有明确提示哪个段对应哪个request的补充,进行二次分析后则可以明确提示:
tshark -n -r <filename> -2
如果是TCP协议,则在三次握手的前两次(SYN和SYN,ACK阶段)两端会协商最小MSS大小(不包括TCP头部+IP头部),这一条TCP流后续的交互包超过MSS则分片传输。

以上只是列举最常见的三个场景,其它场景不一一举例,进行二次分析往往可以更人性化提示前后报文的依赖相关性。
8.设置时间戳格式(-t)
0)总览
支持的格式及说明如下:
| 格式 | 说明 |
|---|---|
| a | 绝对时间,抓包的实际时间,不显示日期; |
| ad | 带日期的绝对时间,显示格式为:YYYY-MM-DD; |
| adoy | 年份的绝对天数,显示格式为:YYYY-DAY; |
| d | delta时间,相对于上一个frame的时间间隔; |
| dd | delta_displayed时间,相对于上一个已显示的frame的时间间隔; |
| e | epoch时间/Unix 时间,从1970 年 1 月 1 日 00:00:00(UTC)开始统计的秒数; |
| r | 相对于第一个包的的相对时间; |
| u | UTC时间,不显示日期; |
| ud | UTC并且带日期的时间,显示为YYYY-MM-DD; |
| udoy | UTC时间并且带日期,天数为这一年的绝对天数,显示为:YYYY-DAY。 |
不指定时默认为r(relative),即相对第一个包的相对时间。
1)当前时区绝对时间(a)
以下面这个包为例,以当前时区的绝对时间显示报文,不显示日期:
tshark -n -r <filename> -t a
2)带日期的当前时区绝对时间(ad)
如果需要在a的基础上显示日期,则使用ad:
tshark -n -r <filename> -t ad
3)年份的绝对天数(adoy)
当需要把天数显示为本年度的绝对天数时(Day Of Year,本年的第几天),使用adoy:
tshark -n -r <filename> -t adoy
这种场景虽不多见,但存在即合理,方便日期之间做加减。
4)相对于上一个报文的时间间隔(d)
相当于上一个报文的时间间隔,则使用d:
tshark -n -r <filename> -t d
5)相对于上一个已显示的报文时间间隔(dd)
此参数和d的区别是,它的相当时间是已经输出在屏幕上的上一个报文的相对时间。
比如使用dd显示所有报文的时间:
tshark -n -r <filename> -t dd
这么看,显示的时间和d几乎是一样的,但如果我只过滤HTTP请求,再使用dd:
tshark -n -r <filename> -Y 'http' -t dd
差别显而易见,当使用HTTP只过滤到两个报文时(frame 4和frame 6):
- 通过dd输出的时间,frame 4作为输出的第一个包作为时间参考系,所以时间为0,frame 6显示的时间是相对于frame 4的间隔时间;
- 通过d输出的时间,frame 4的时间是相对于frame 3的间隔时间,frame 6的时间相对于frame 5的间隔时间。
所以不难看出,dd的含义是:delta displayed,已经显示了的报文的相对时间。
6)epoch时间/Unix时间(e)
epoch时间/Unix 时间,从1970 年 1 月 1 日 00:00:00(UTC)开始统计的秒数:
tshark -n -r <filename> -t e
7)相对于第一个包的的相对时间(r)
显示相对于第一个包(frame 1)的相对时间,则可以使用r:
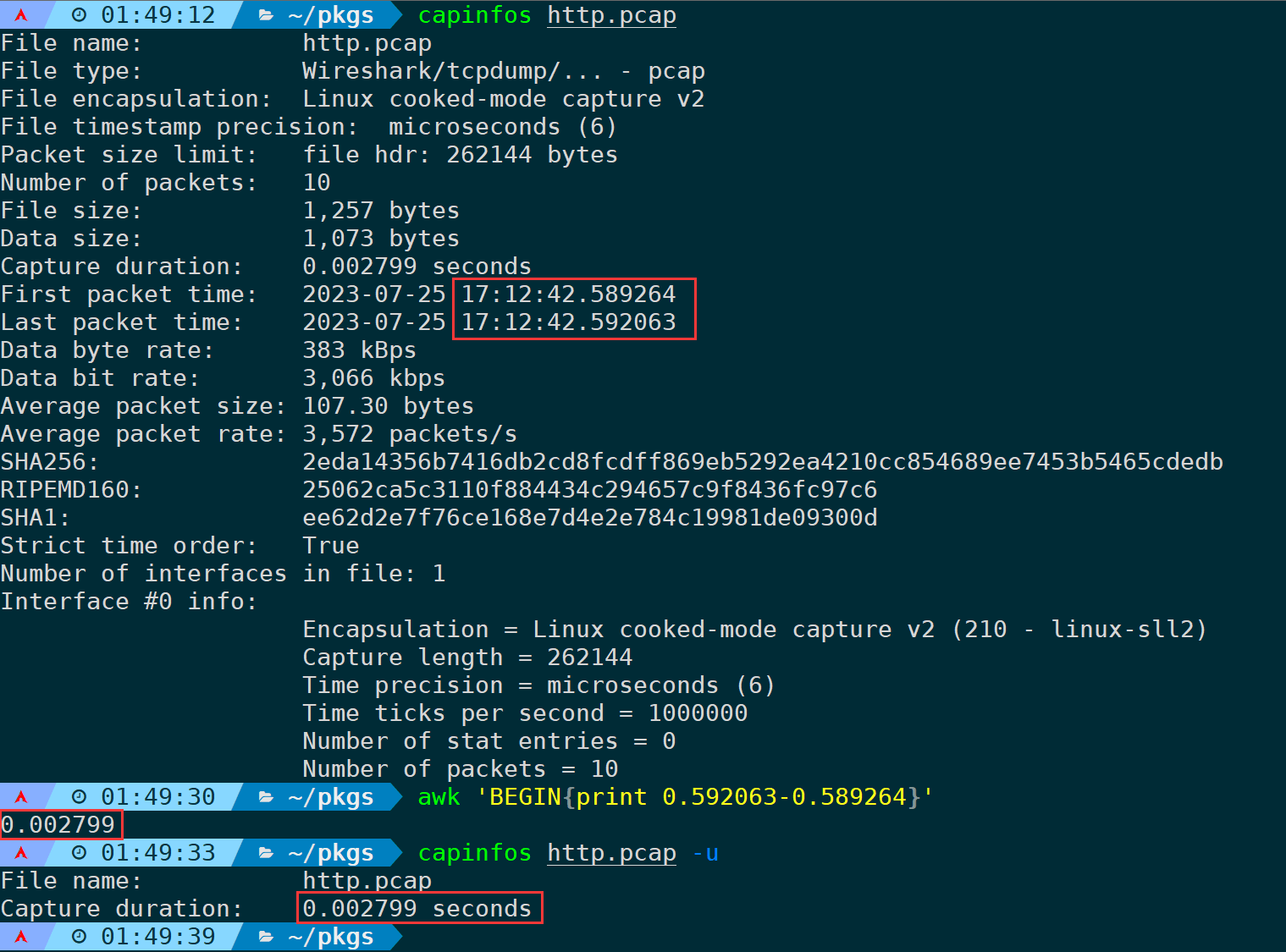
tshark -n -r <filename> -t r
以最后一个包(frame 10)为例,显示时间间隔为:0.002799,实际上是相对于第一个包的时间,通过capinfos也可以看出首尾包的差距刚好等于这个时间间隔:
8)不显示日期的UTC时间(u)
以UTC时间显示,并且不显示日期,则可以使用u:
tshark -n -r <filename> -t u
9)显示日期的UTC时间(ud)
在UTC的基础上显示带日期的UTC时间:
tshark -n -r <filename> -t ud
10)年度绝对天数的UTC时间(udoy)
显示UTC带日期的时间,其中天数显示为Day Of Year格式,即本年度的第几天:
tshark -n -r <filename> -t udoy
9.筛选过滤报文(-Y)
此选项常用,用来过滤分析符合过滤表达式的报文,相当于wireshark最上面的过滤筛选栏功能。
上面的一些示例中,其实已经用到了-Y选项来过滤报文,只要你写的过滤表达式符合wireshark语法,就能被正常执行,wireshark语法可以参考官方文档。
1)示例1:通过http.host过滤
想过滤到http host为某个值,可以是:
tshark -n -r <filename> -Y 'http.host == "web-server1"'
2)示例2:过滤TCP重传、快速重传、DUP ACK的包
过滤TCP重传、快速重传、DUP ACK的包,可以是:
tshark -n -r <filename> -Y 'tcp.stream eq 2 && ( tcp.analysis.retransmission or tcp.analysis.fast_retransmission or tcp.analysis.duplicate_ack )' -t d
通过-t d来显示相对上一帧的时间,tcp.stream eq 2来指定第三条TCP流。
3)示例3:过滤ARP报文
过滤ARP报文,取出特定帧,可以是:
tshark -n -r <filename> -Y 'arp && frame.number in {9,10,197,208,216}' -t d
4)示例4:过滤第一次握手的请求
第一次握手只发送SYN,ACK位置0,因此可以这么写过滤规则:
tshark -n -r http-keep-alive.pcap -Y 'tcp.flags.syn==1&&tcp.flags.ack==0'
以上只是几个示例,涉及到各个场景的过滤用法,-Y都能完全支持。
10.统计分析报文(-z)
使用tshark -z help 可以查看支持的统计分析选项。
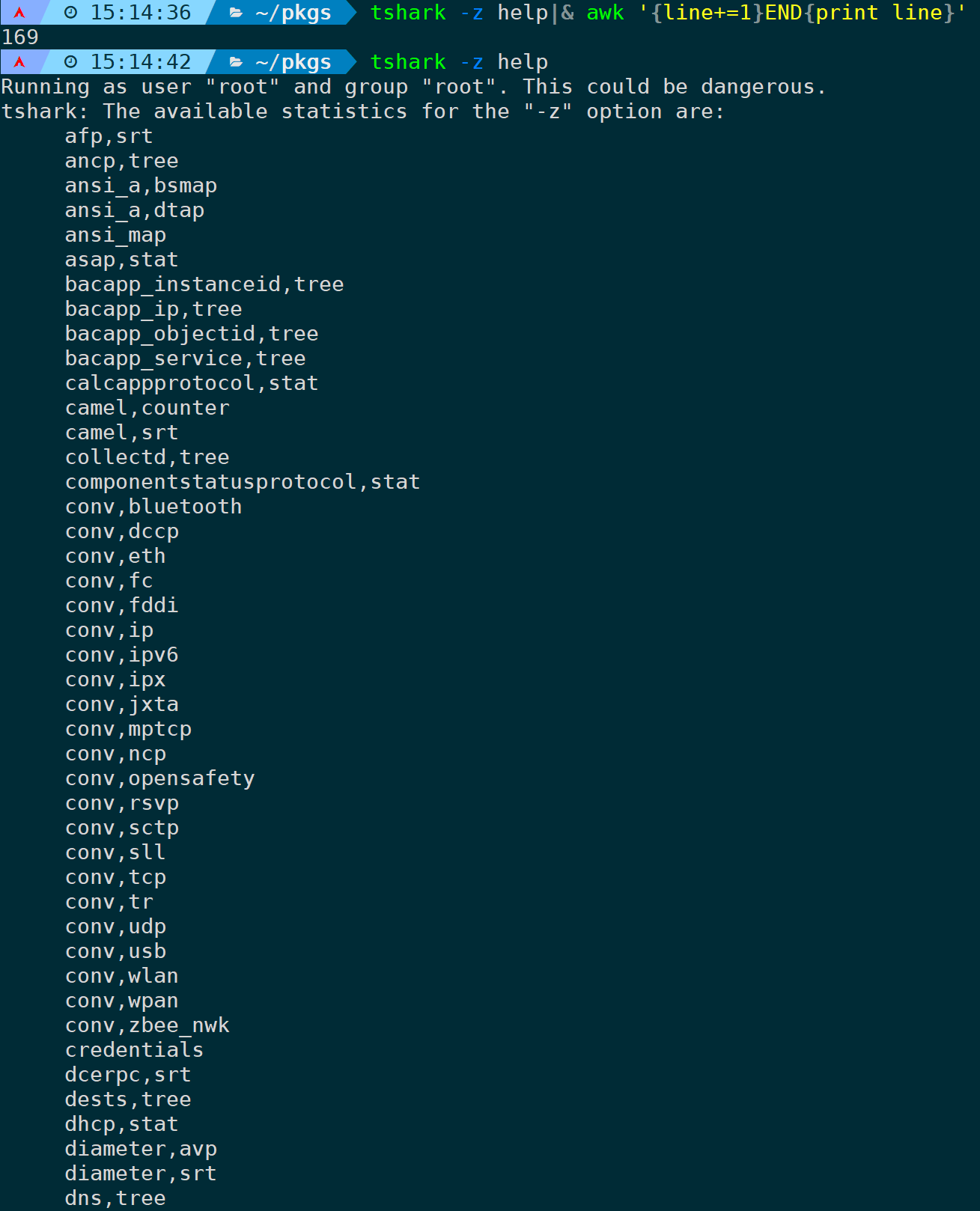
目前为止有169个统计分析选项,但常用的并不多。
下面将一一举例最常见的一些示例常见,如果你遇到的需要统计分析的场景并不在举例场景中,那么通过-z help去查看相匹配的场景选项即可。
1)统计分析IP会话(conv,ip)
会话统计需要用到‘conv,’作为前缀,表示的是conversation。
以这一条TCP流为例,统计会话:
tshark -n -r <filename> -z 'conv,ip'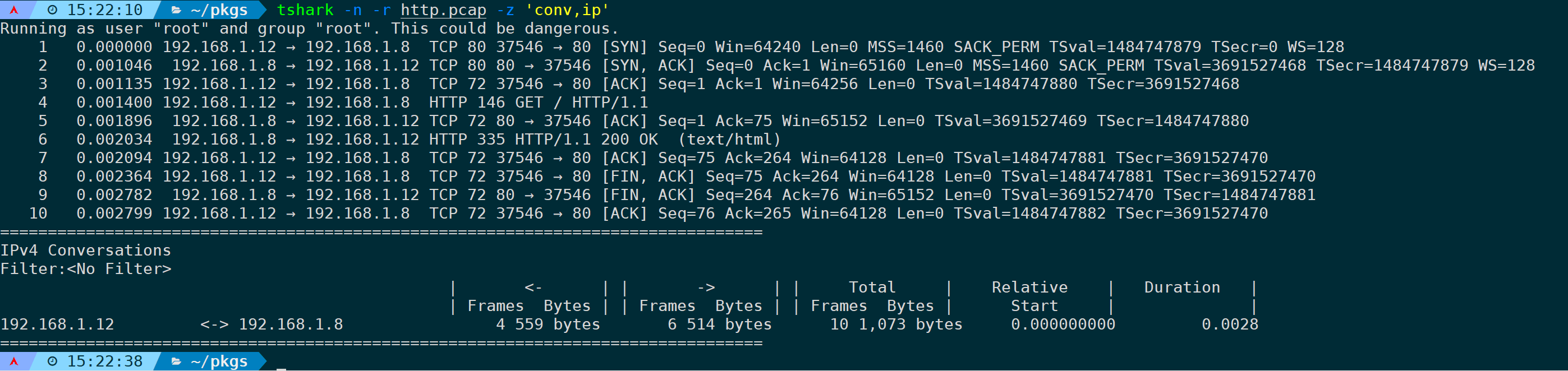
可以通过-q参数来让它只输出统计结果,不显示报文:
tshark -n -q -r <filename> -z 'conv,ip'
如果是ipv6地址,改成-z ‘conv,ipv6’即可。
当然,也可以在统计结果后面来写过滤规则,比如只统计第一条流的结果:
tshark -n -q -r <filename> -z conv,ip,tcp.stream==0
2)统计分析TCP会话(conv,tcp)
和第一个示例的区别只是统计的层级不一样,conv,ip 统计IP层,那么conv,tcp则统计tcp头部,既然是TCP层,肯定会有端口存在:
tshark -n -q -r <filename> -z conv,tcp
当然它也支持过滤选项:
tshark -n -q -r <filename> -z conv,tcp,tcp.port==443
或者,我只想要第二个的流的统计数据:
tshark -n -q -r <filename> -z conv,tcp,'tcp.stream eq 2'
3)统计分析UDP会话(conv,udp)
通过以上两个示例,你也可以猜到统计命令应该写成下面这样:
tshark -n -q -r <filename> -z conv,udp
过滤规则如果有多条或者空格,可以通过单引号引起来:
tshark -n -q -r <filename> -z conv,udp,'udp.port in {8000,8803}'
4)统计分析DNS层次结构(dns,tree)
分析DNS层级结构信息可以是:
tshark -n -q -r <filename> -z dns,tree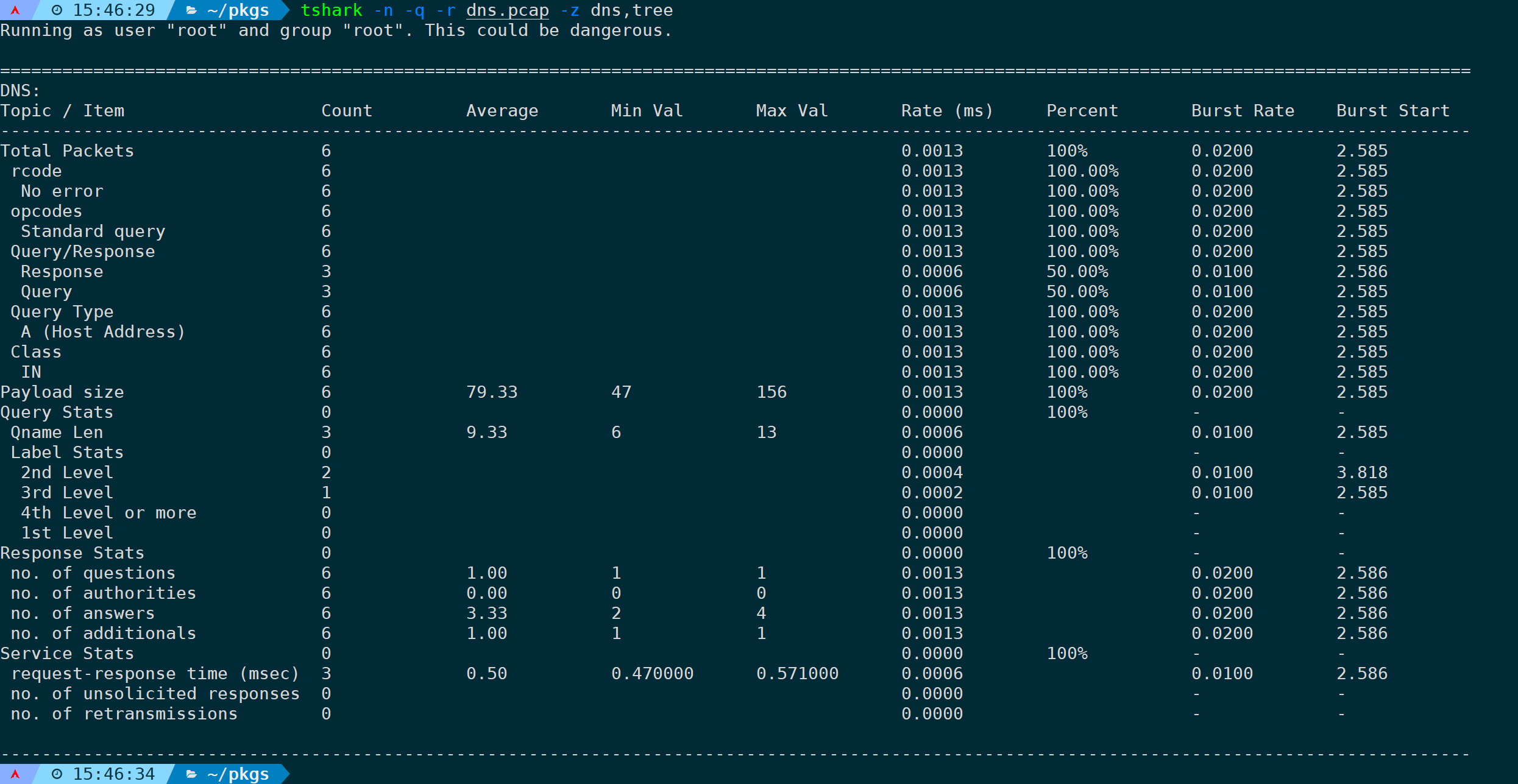
将会统计报文中所有设计到dns协议的,响应时间、响应速率、各类查询类别、payload大小、附加记录及各类属于DNS头部字段的统计信息。
当然它也支持过滤选项,比如只统计dns query baidu.com的请求,可以是:
tshark -n -q -r <filename> -z dns,tree,dns.'qry.name == baidu.com'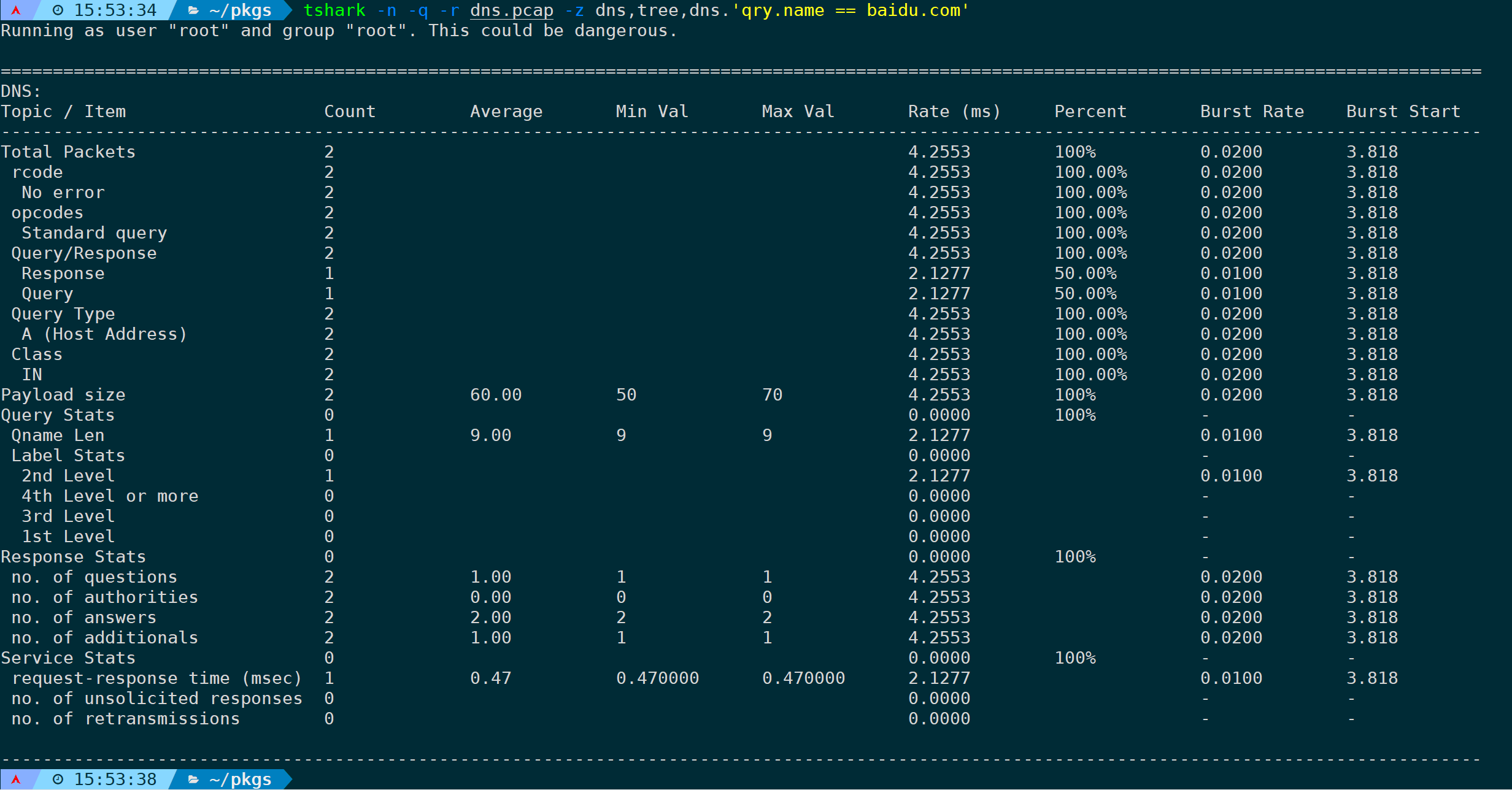
5)统计分析IP端点(endpoints,ip)
端点将只关注单个数据包中,源目的通信情况。
比如统计IP层,每个IP流入流出流量、包量可以是:
tshark -n -q -r <filename> -z endpoints,ip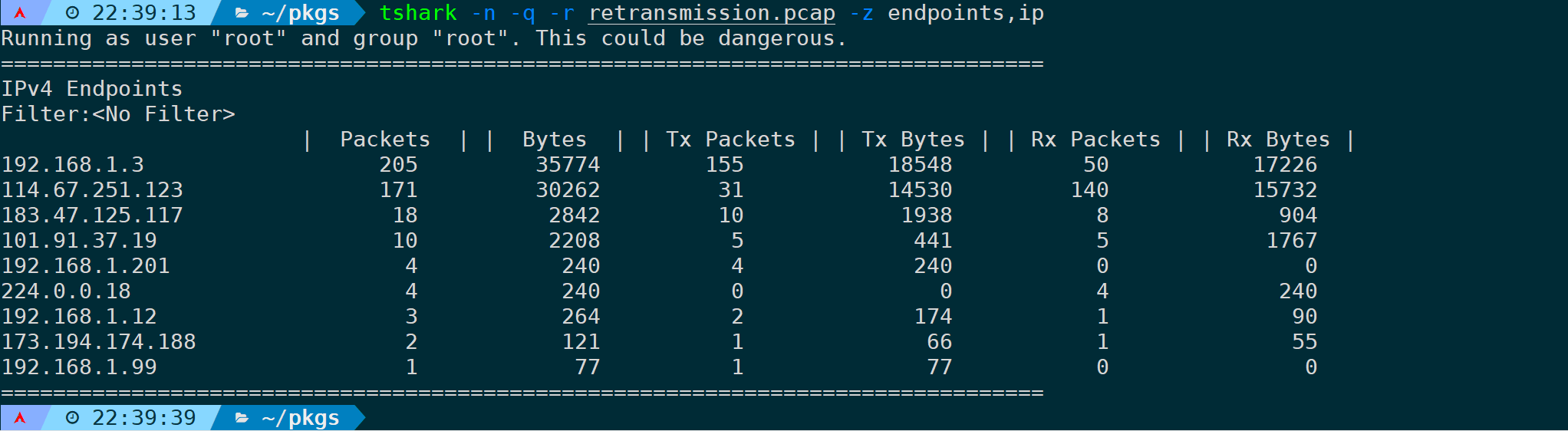
conv则会关注整个会话的情况。
当然,它也能指定过滤规则,比如只统计涉及到TLS传输的数据:
tshark -n -q -r <filename> -z endpoints,ip,'tls'
6)统计分析TCP端点(endpoints,tcp)
将会分析单个数据包的TCP头部维度,汇总统计:
tshark -n -q -r <filename> -z endpoints,tcp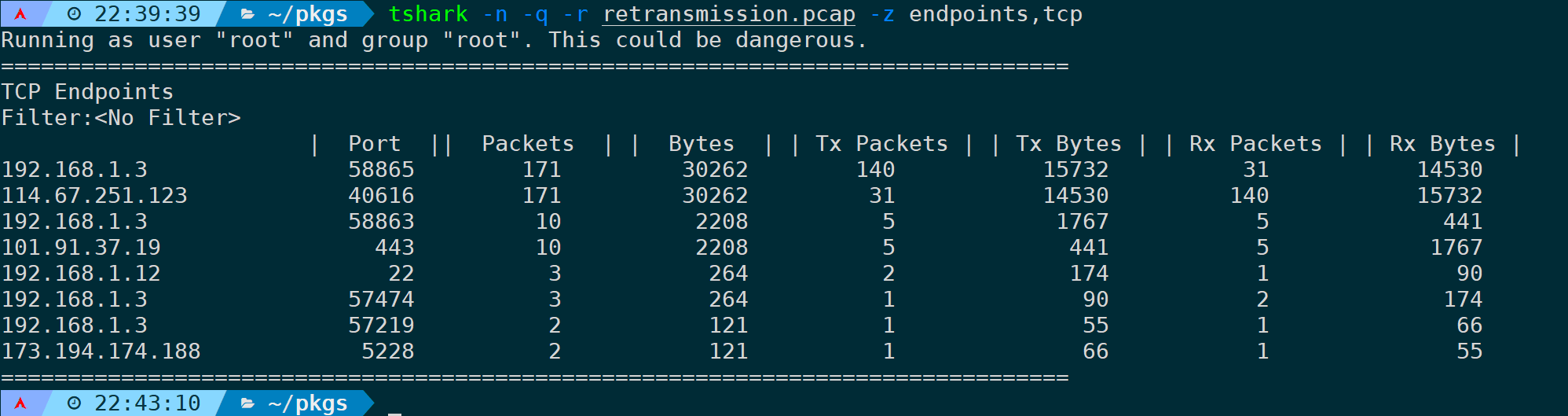
既然是TCP传输层,那么显而易见会有端口。
同理,它也支持指定过滤规则,过滤tls或者通信端口为58865、5228的数据可以是:
tshark -n -q -r <filename> -z endpoints,tcp,'tls||tcp.port in {58865,5228}'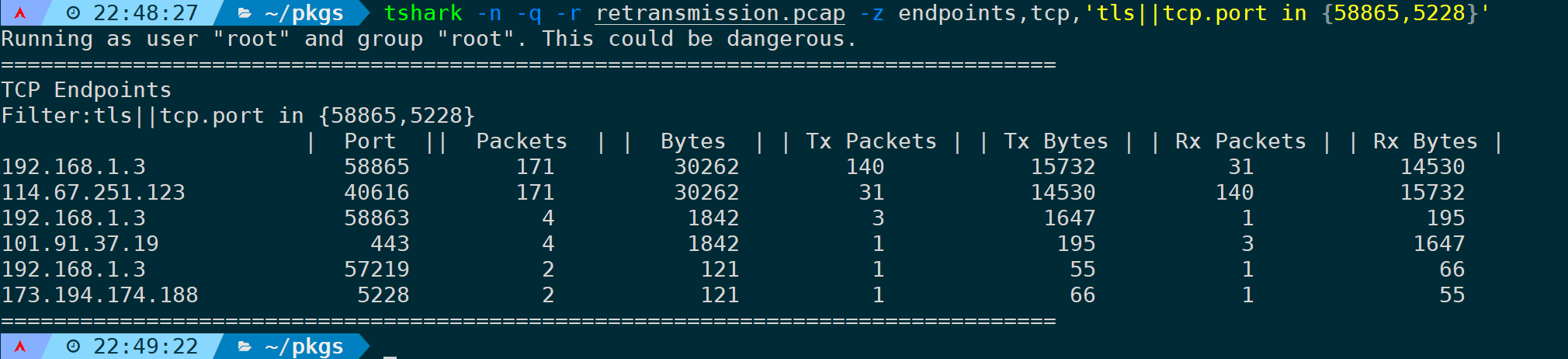
7)统计分析UDP端点(endpoints,udp)
很好,你已经会举一反三了,统计分析UDP端点数据:
tshark -n -q -r <filename> -z endpoints,udp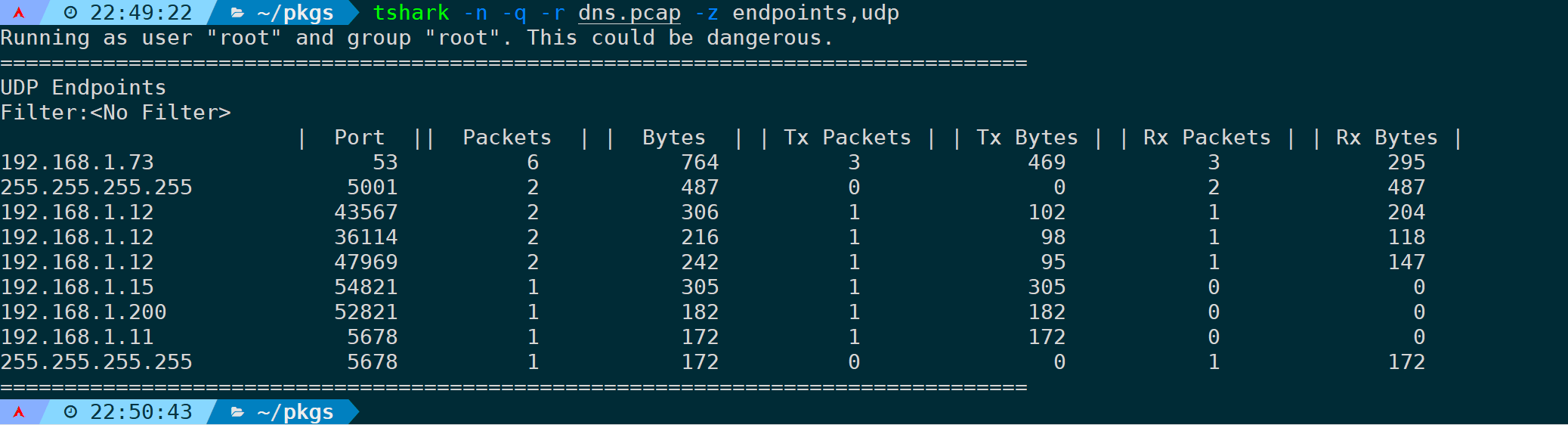
指定过滤规则,只过滤涉及到DNS的数据:
tshark -n -q -r <filename> -z endpoints,udp,dns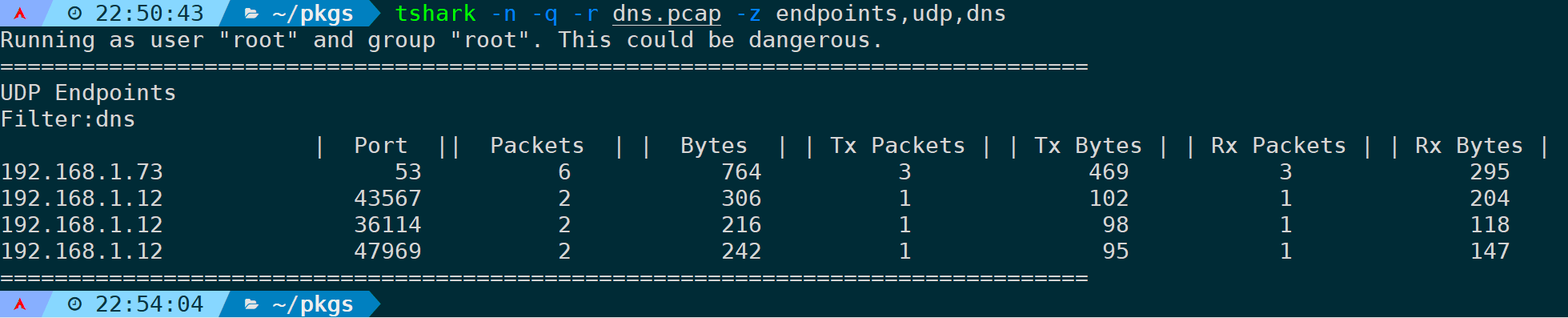
8)以专家模式输出汇总(expert)
对应wireshark的专家信息功能,在wireshark上的展示如下:

在tshark上的实现则是:
tshark -n -q -r <filename> -z expert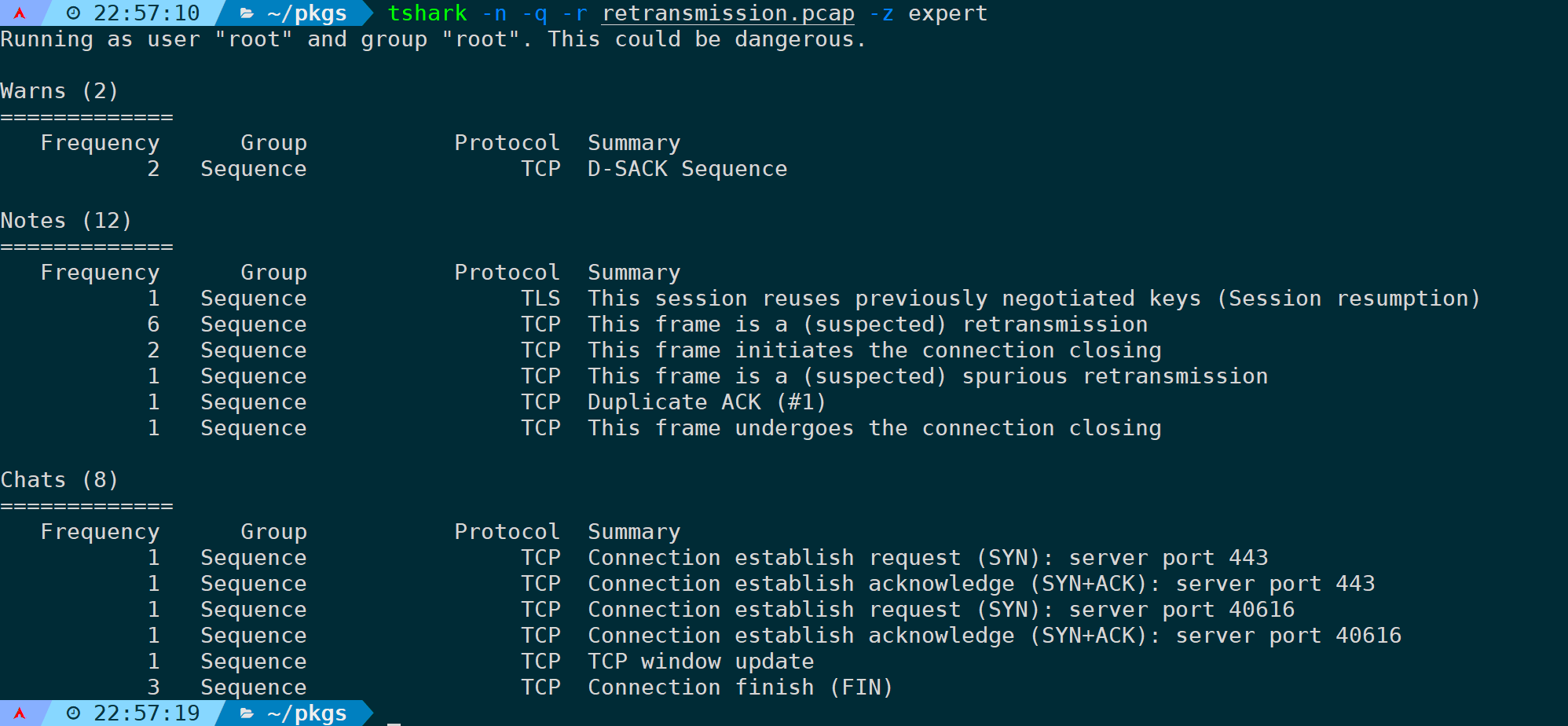
它也支持指定过滤选项,比如只分析第三个流,可以是:
tshark -n -q -r <filename> -z expert,'tcp.stream==2'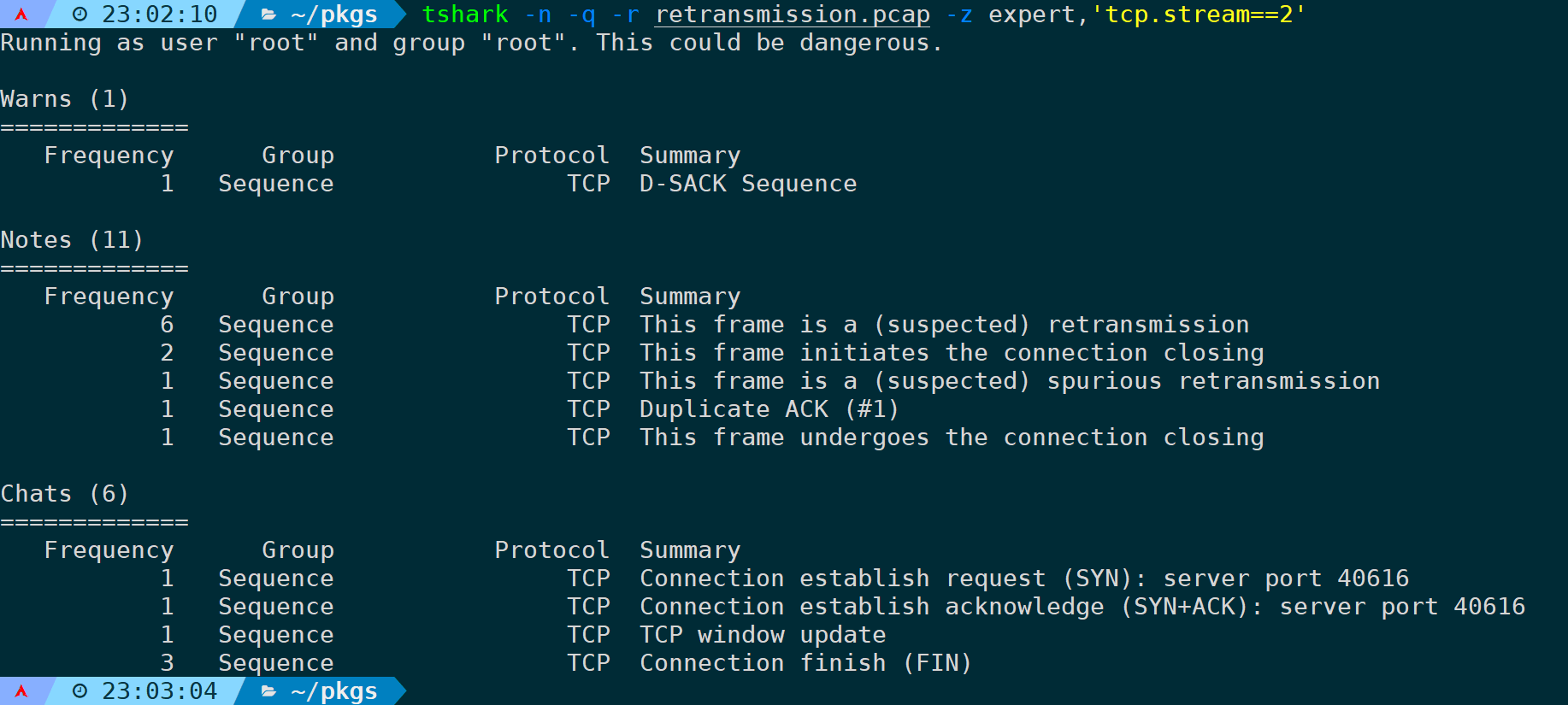
注意:如果不是一条完整的流(比如缺失TCP三次握手),那么则可能不会有任何输出。
过滤警告级别的统计数据,可以是:
tshark -n -q -r <filename> -z expert,'Warns'
9)以流量图形式显示两个端点的通信过程(flow)
对应wireshark的Flow Graph功能,即流量图显示功能,可以把整个通信过程画出一个通信图出来,在wireshark上的显示如下:
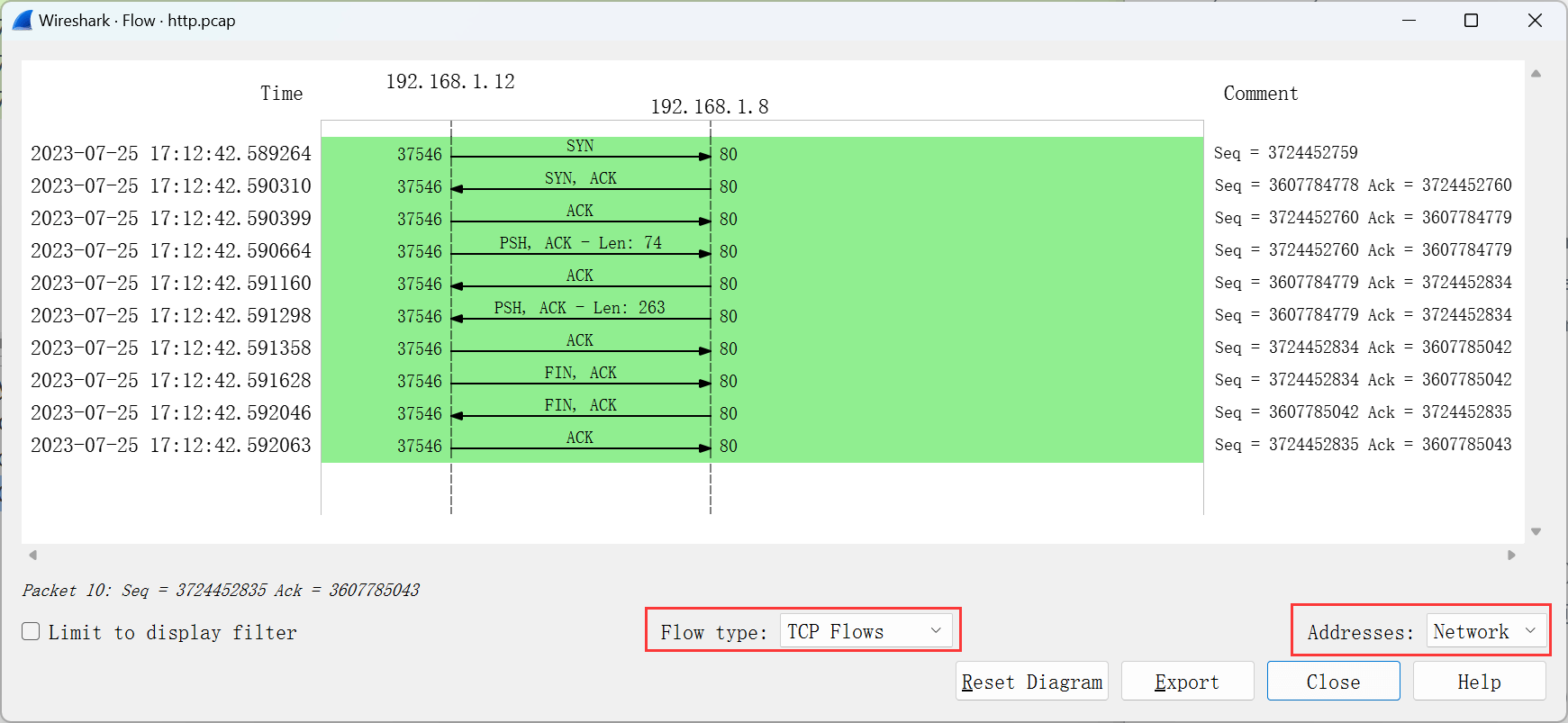
那么在tshark的实现,可以是:
tshark -q -n -r <filename> -z flow,tcp,network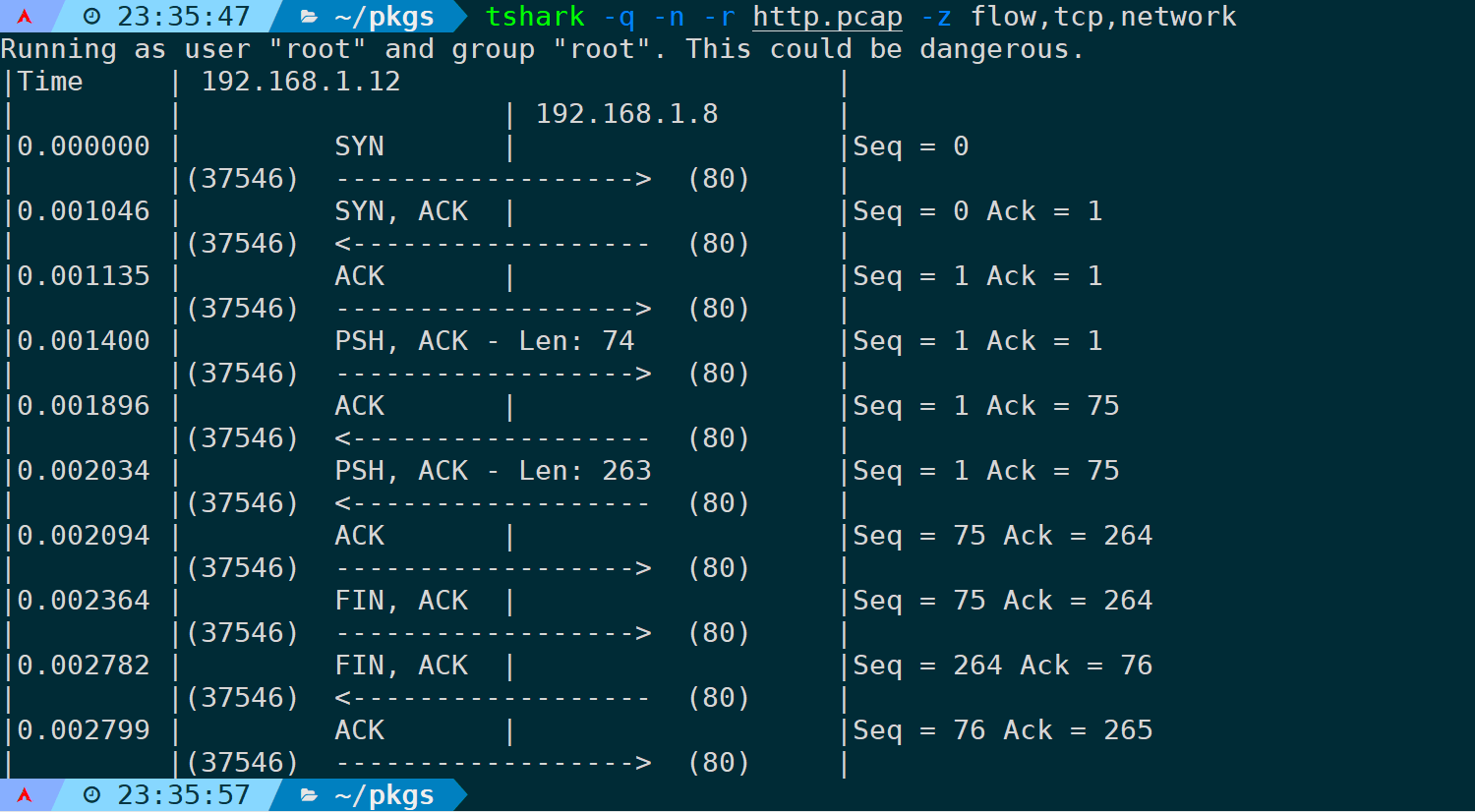
可以看到,tshark用ASCII字符制表输出,并非真正意义上的图形化界面。
时间上,wireshark默认是ad形式,如果你想的话,当然可以通过-t ad来指定。
流图形的参数格式为:flow,name,mode[,filter]
flow是固定字段,name取值范围为:
- any:所有报文
- icmp:icmp
- icmpv6:icmpv6
- lbm_uim:UIM
- tcp:TCP
mode取值范围为:
- standard:所有地址
- network:网络地址
[,flter]则为具体的过滤规则,符合wireshark语法就行。
再来看一个示例,图形化显示ICMP的交互过程:
tshark -q -n -r <filename> -z flow,icmp,network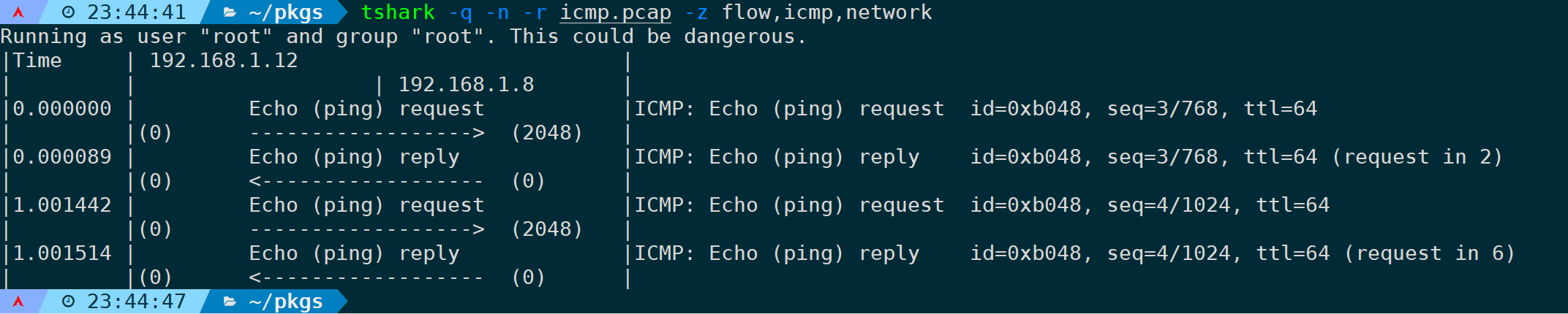
可以看到一共有两个ICMP request对应两条reply,但报文关联信息字段,只有reply报文的尾部显示了回应给哪个request,request in 2表示第二帧,request in 6表示第六帧。
结合前面讲到过的二次分析(two-pass)场景,不妨指定-2参数看看效果:
tshark -q -2 -n -r <filename> -z flow,icmp,network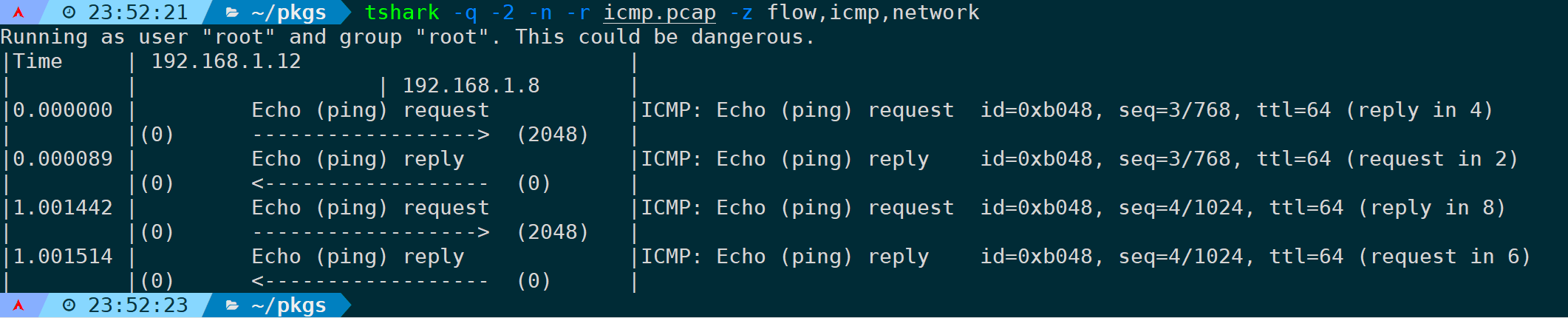
可见request对应的reply在第几个frame,会被完整的填充。
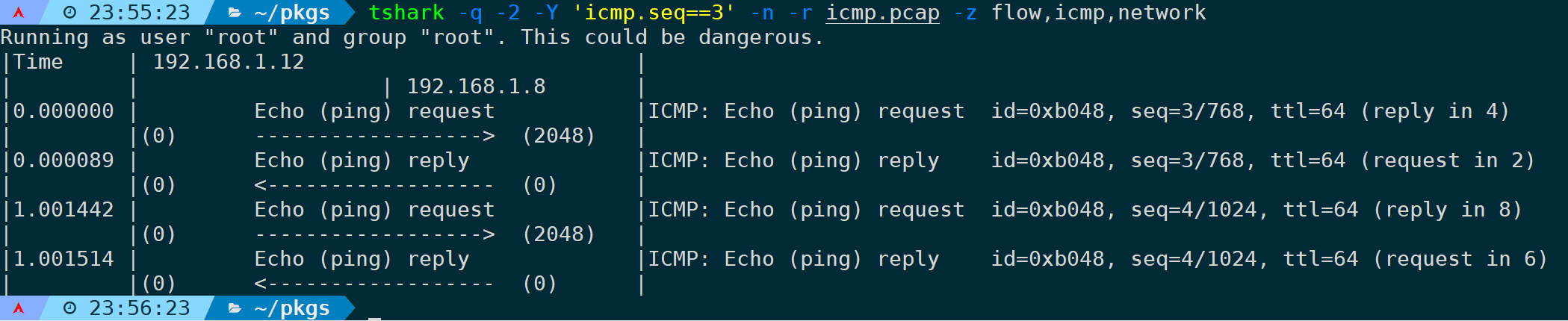
当然,再最后面可以指定过滤规则,比如过滤icmp.seq==3:
tshark -q -2 -n -r <filename> -z flow,icmp,network,icmp.seq==3
不要通过-Y来指定过滤规则,并不会生效:
10)显示两个节点之间的TCP/UDP流内容(follow)
此选项格式为:follow,prot,mode,filter[,range]
follow是固定字段,prot表示传输协议(Protocols),可取范围如下:
| 取值 | 含义 |
|---|---|
| tcp | TCP协议 |
| udp | UDP协议 |
| dccp | DCCP协议 |
| tls | TLS 或 SSL 协议 |
| http | HTTP流 |
| http2 | http2流 |
| quic | quic流 |
mode来指定输出格式,取值如下:
| 取值 | 含义 |
|---|---|
| ascii | ASCII格式输出,不可打印字符用点表示 |
| ebcdic | EBCDIC格式输出,不可打印字符用点表示 |
| hex | 带偏移量的十六进制和ASCII数据 |
| raw | 十六进制数据 |
| yaml | YAML格式 |
filter用来指定要显示的流,有如下三种格式:
| 格式 | 含义 |
|---|---|
| ip-addr0:port0,ip-addr1:port1 | 指定IP地址和TCP、UDP或DCCP端口对(TCP端口用于TLS、HTTP和HTTP2;QUIC不支持地址和端口匹配); |
| stream-index | 指定流索引,用于TCP、UDP、DCCP、TLS和HTTP(TLS和HTTP使用TCP流索引); |
| stream-index,substream-index | 指定流和子流,用于HTTP/2和QUIC,因为它们使用多路复用/长连接(HTTP/2的TCP流和HTTP/2流索引、QUIC连接号和流ID)。 |
[,range]用于指定应该显示流的哪些部分。
①示例一:以“十六进制”格式显示第一个TCP流的内容
tshark -q -n -r <filename> -z "follow,tcp,hex,0"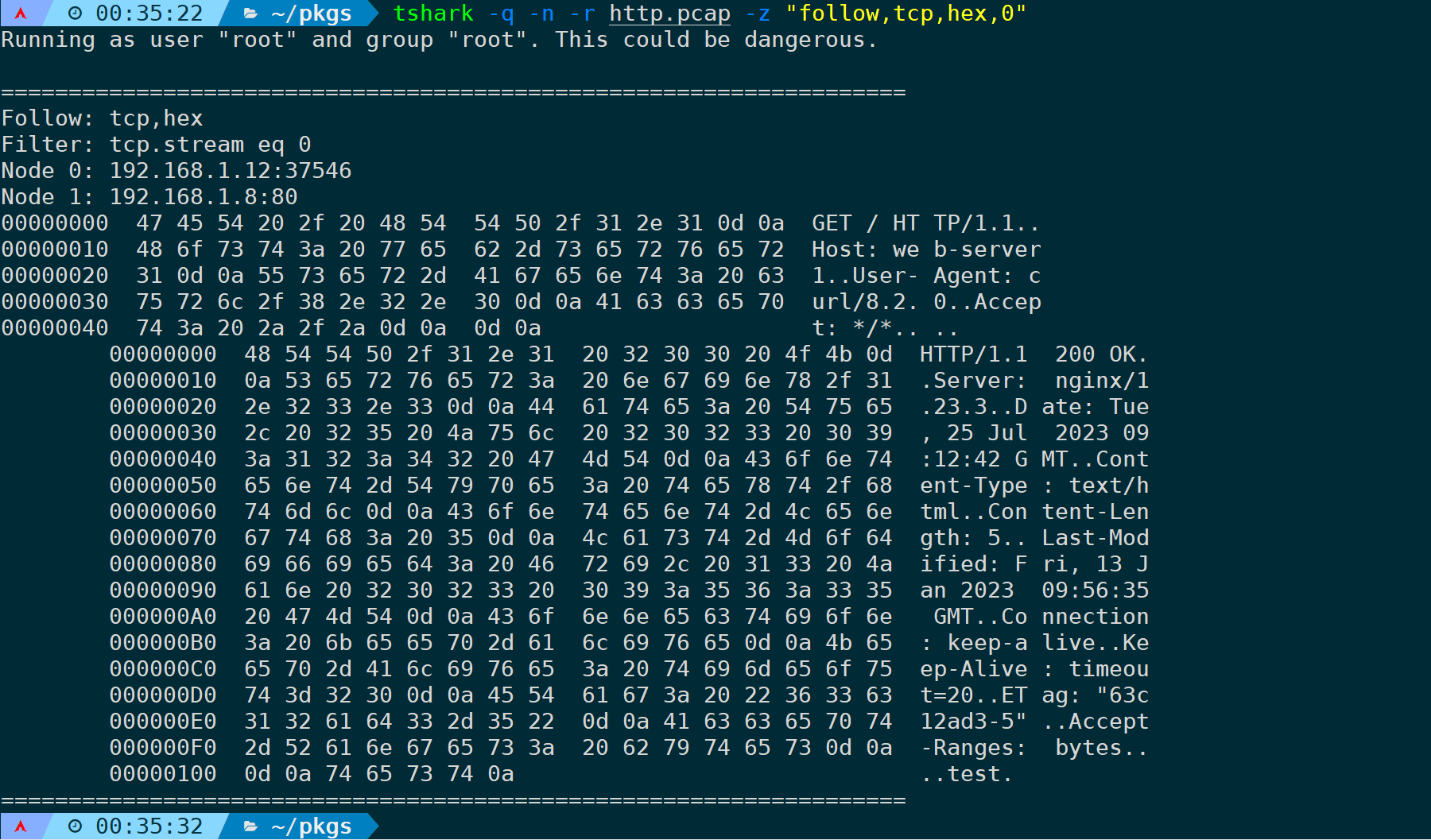
可以清晰看到,Node0请求Node1的80端口,Node0发送了HTTP GET请求给Node1,之后拿到了Node1的200 OK HTTP响应状态码,上下两段通过多个空格隔开,方便区分。
②示例二:显示IP1:PORT1和IP2:PORT2之间的TCP流的内容
tshark -q -n -r <filename> -z "follow,tcp,ascii,IP1:PORT1,IP2:PORT2"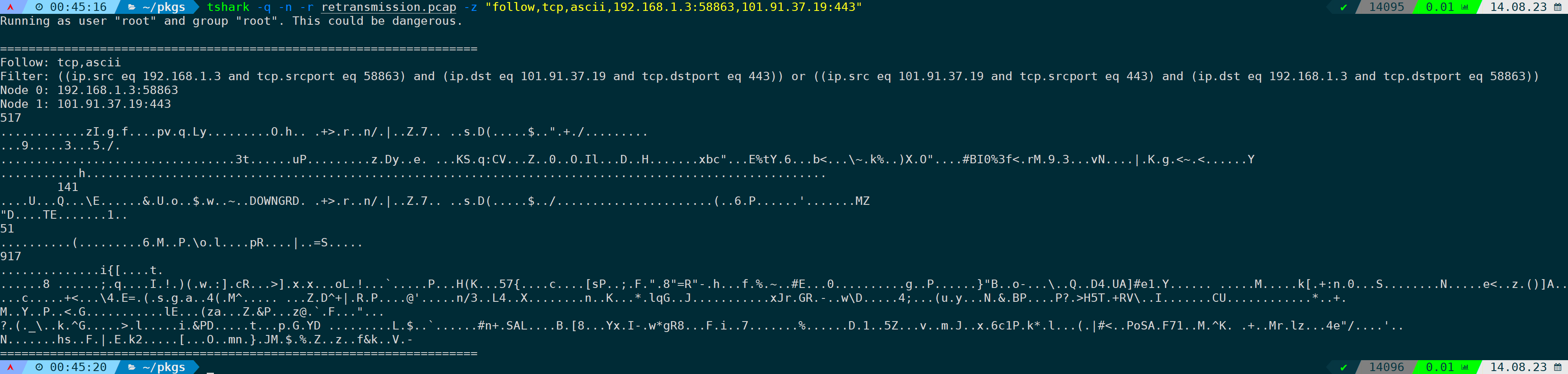
这条流为tls流,数据被加密了,所以看不出有意义的内容。从截图不难看出,Filter规则会根据我们写的规则进一步转换填充为wireshark的完整过滤语法,即:
((ip.src eq 192.168.1.3 and tcp.srcport eq 58863) and (ip.dst eq 101.91.37.19 and tcp.dstport eq 443)) or ((ip.src eq 101.91.37.19 and tcp.srcport eq 443) and (ip.dst eq 192.168.1.3 and tcp.dstport eq 58863))③示例三:在第一个TCP连接中显示第一个HTTP的内容
tshark -q -n -r <filename> -z "follow,http,hex,0,1"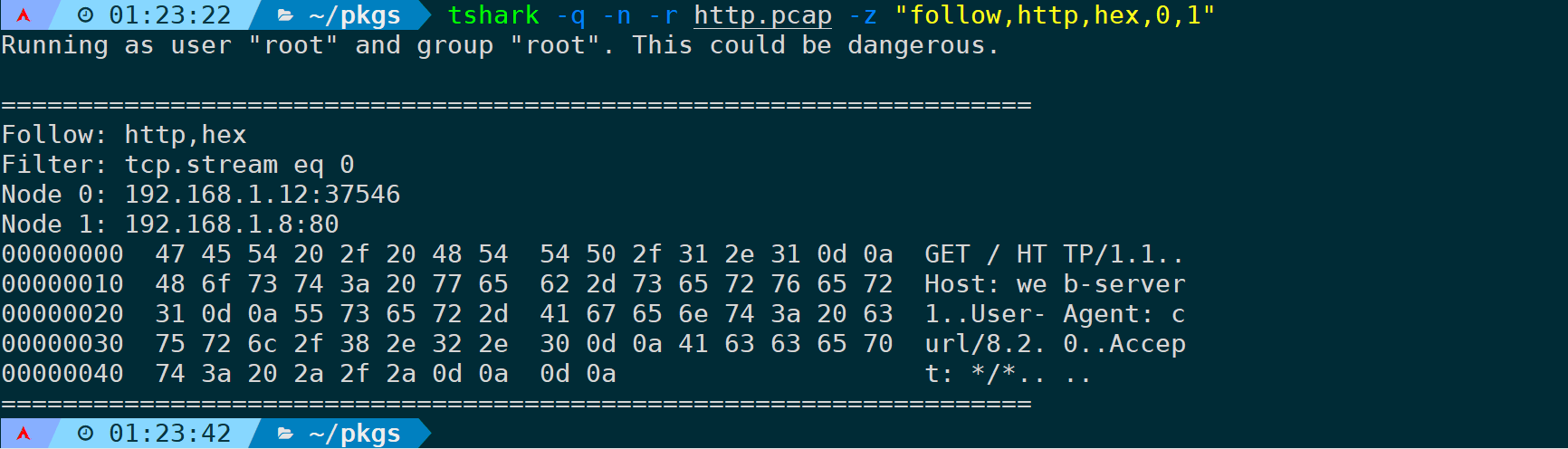
第一个HTTP为GET,那么第二个HTTP为response:
tshark -q -n -r <filename> -z "follow,http,hex,0,2"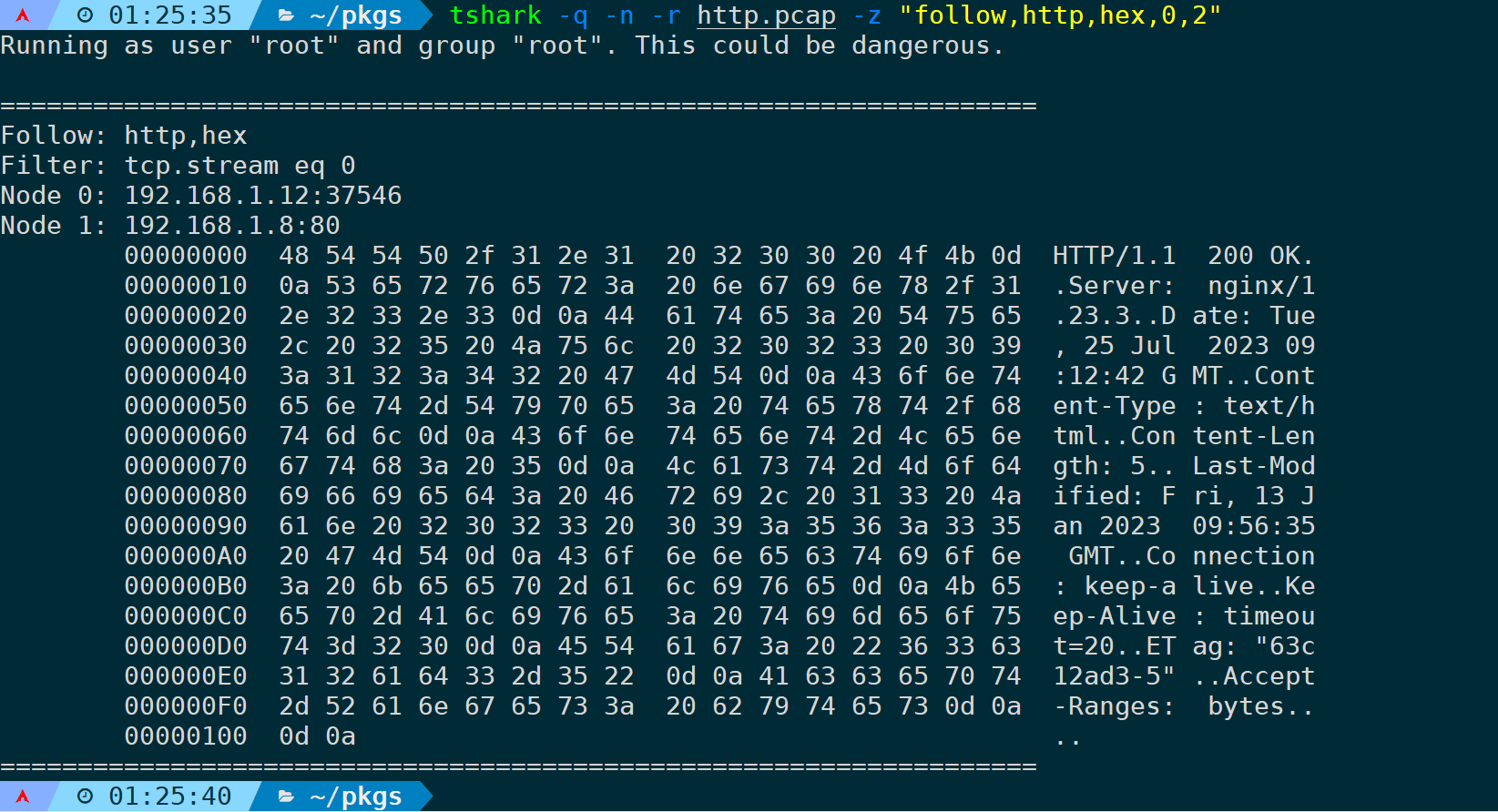
如果是长连接,一个TCP连接中有多个HTTP请求,修改最后面的数字即可:
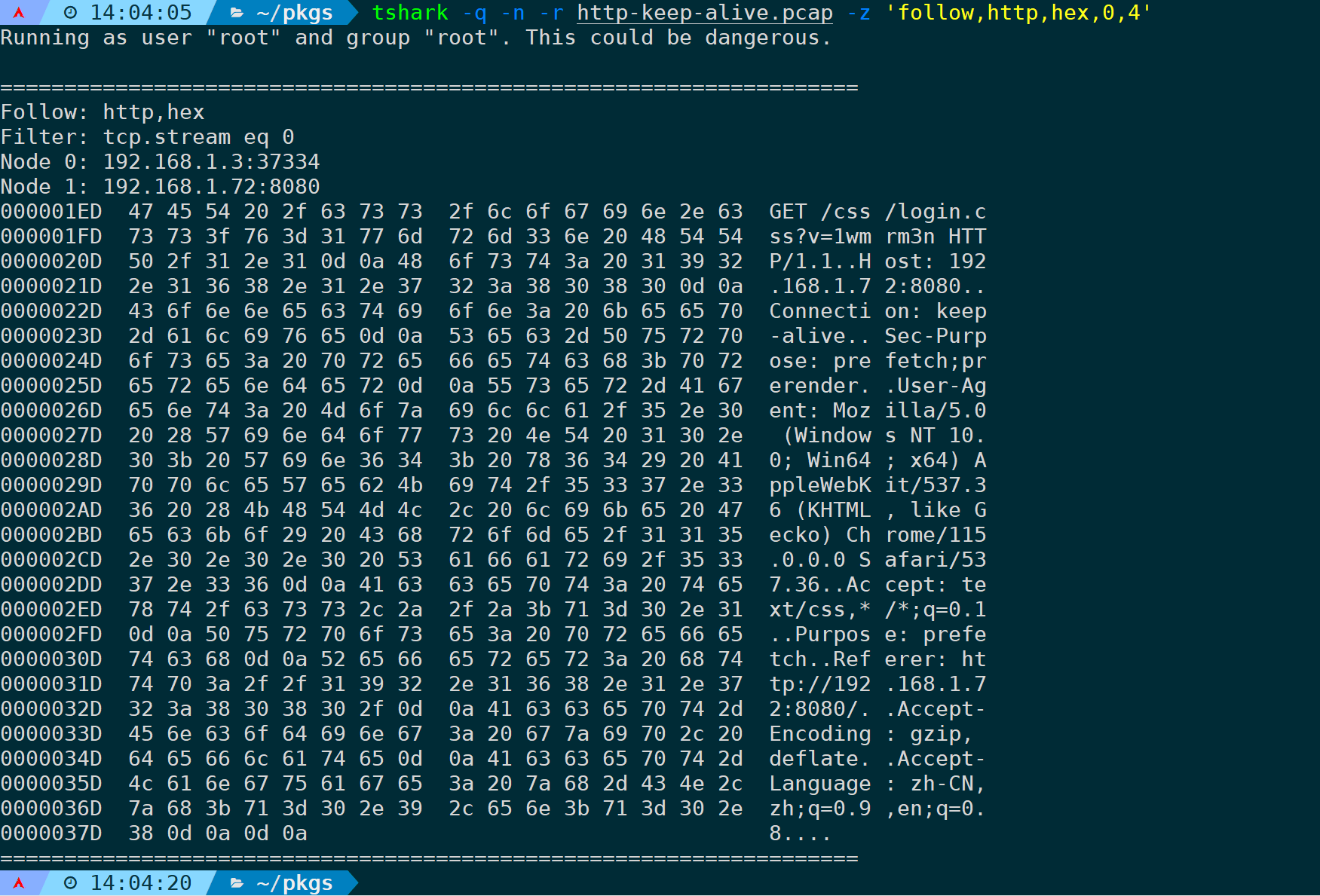
此时还是在第一条TCP流中(tcp.stream==0),过滤的第4条HTTP请求的内容。
11)统计分析HTTP状态(http,stat)
统计分析HTTP的状态码以及请求方法,可以使用如下命令:
tshark -q -n -r <filename> -z http,stat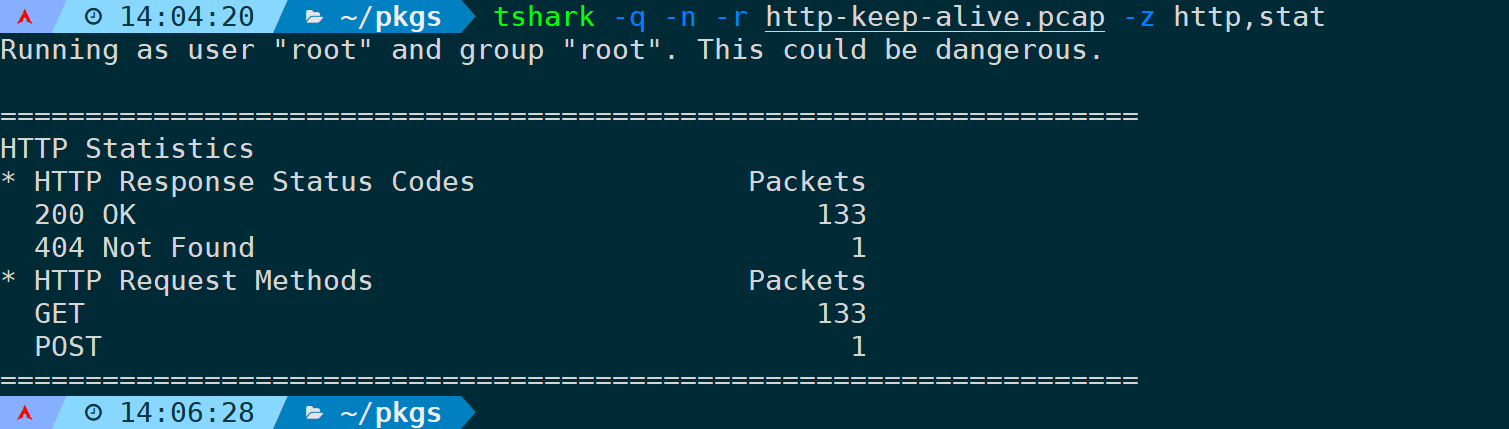
可以看到整个报文中,有133个200 OK、1个404状态码,以及133个GET和1个POST请求方法。
它自然也支持应用过滤规则,比如只过滤第一条TCP流对应的HTTP状态码和请求方法,可以是:
tshark -q -n -r <filename> -z http,stat,'tcp.stream==0'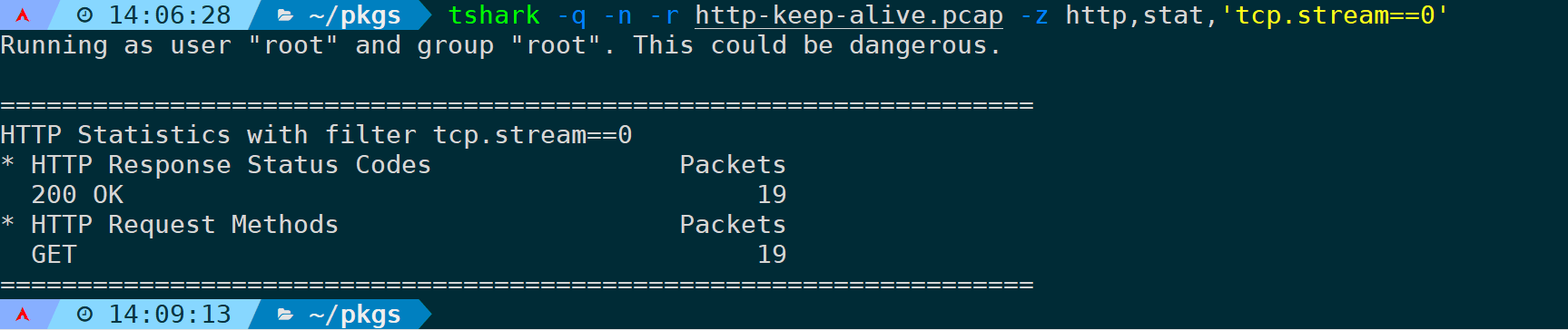
12)统计分析HTTP树状结构(http,tree)
统计HTTP数据包分布。输出结果为响应状态代码和请求方法:
tshark -q -n -r <filename> -z http,tree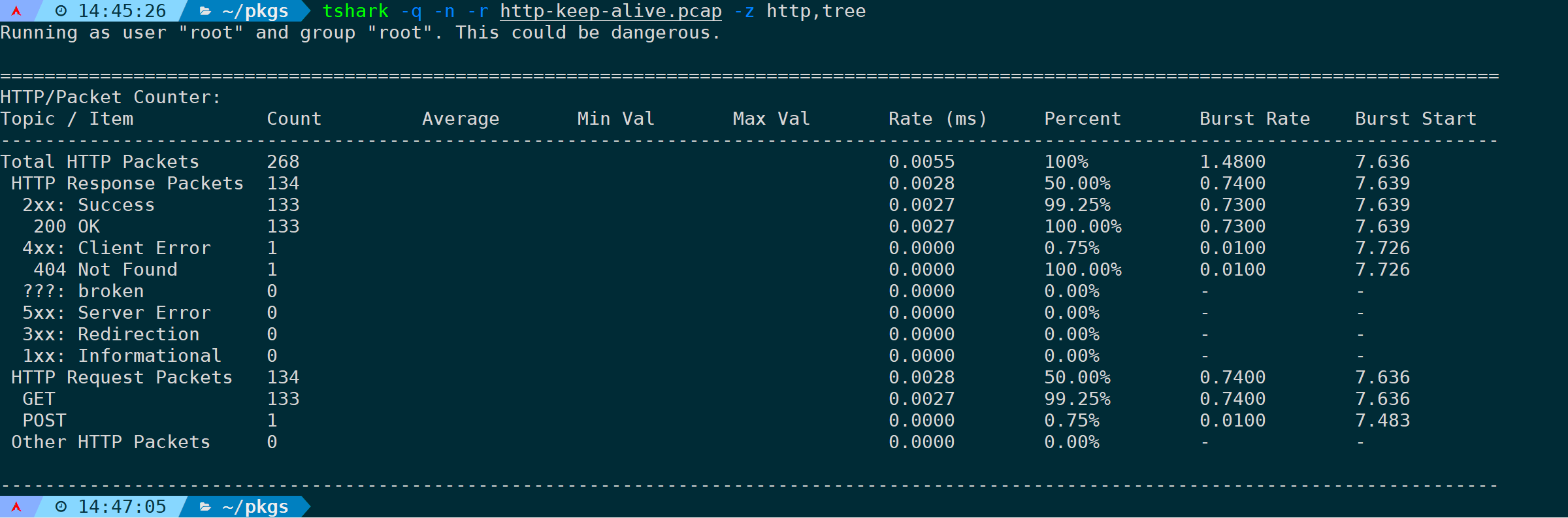
当然也支持在最后面加过滤规则。如果是HTTP2协议,则使用http2,tree。
13)统计分析HTTP请求的URI路径(http_req,tree)
http_req,tree 只会统计请求涉及到的URI资源路径,不关注响应:
tshark -q -n -r <filename> -z http_req,tree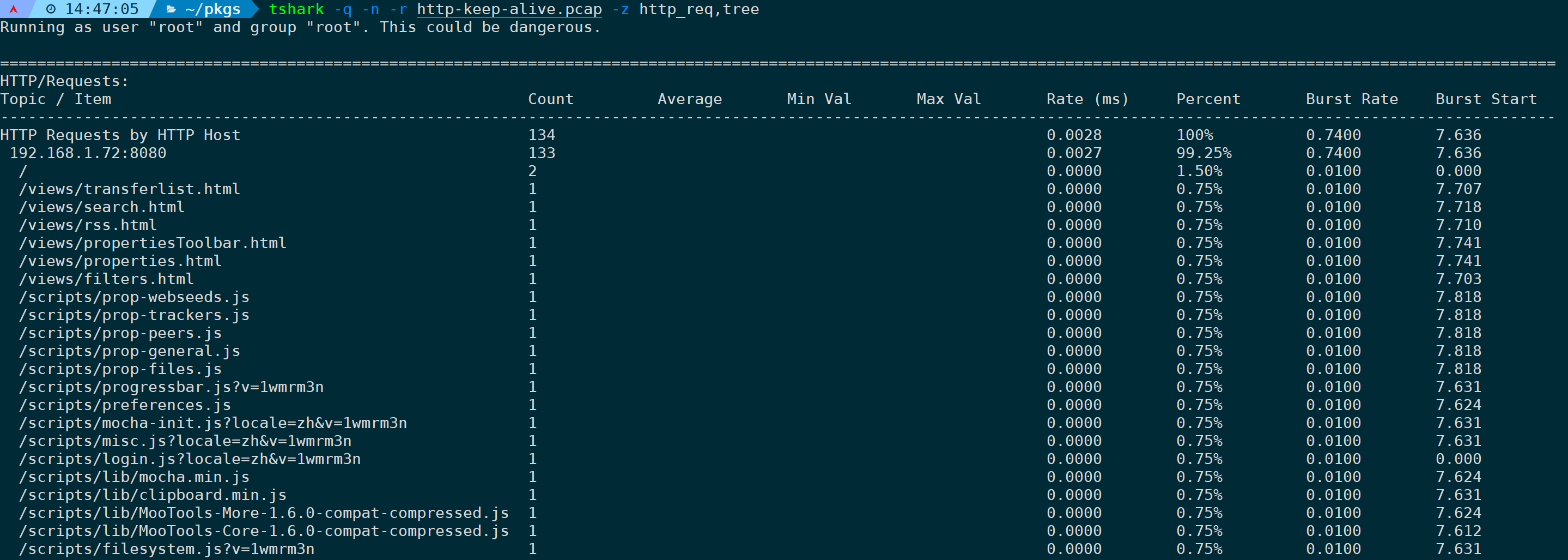
指定规律规则,只过滤第一条TCP连接的数据:
tshark -q -n -r <filename> -z http_req,tree,'tcp.stream==0'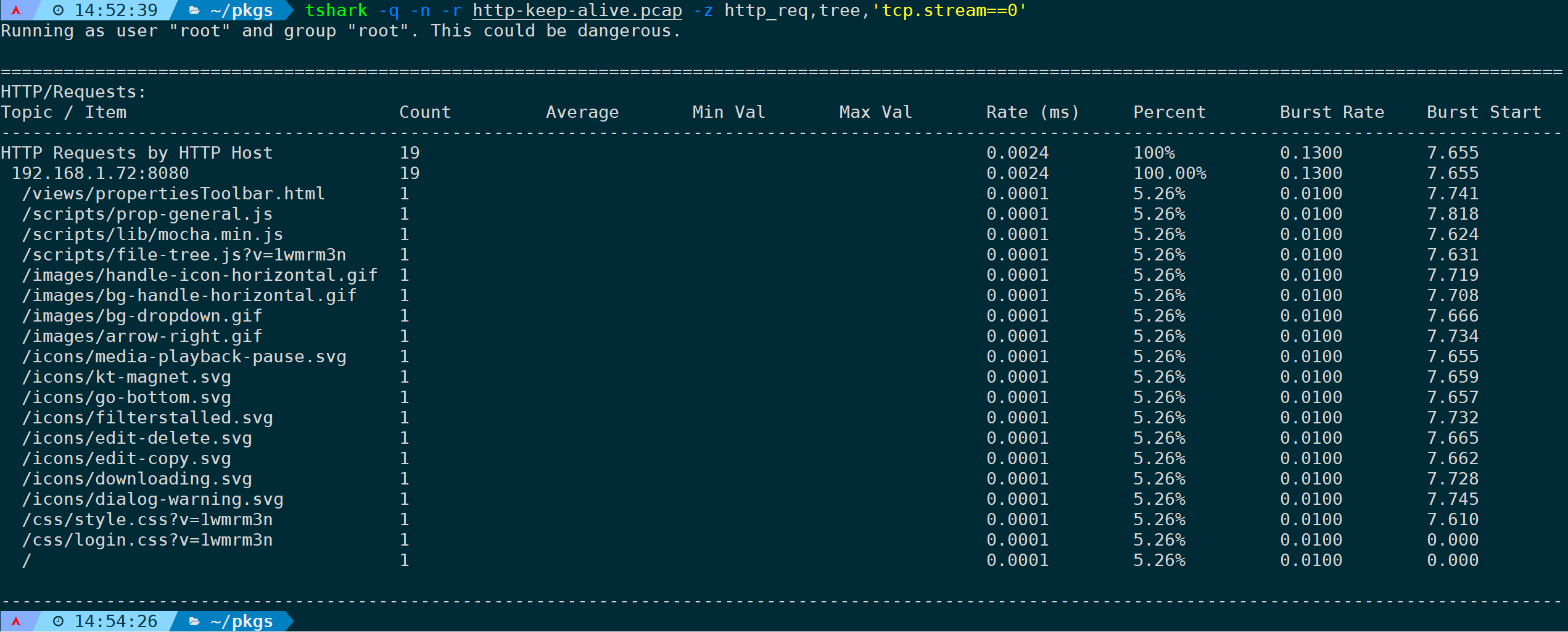
14)统计分析HTTP请求URL(http_seq,tree)
和http_req,tree的区别是,它会自动补齐请求的服务器,以URL路径方式呈现出来:
tshark -q -n -r <filename> -z http_seq,tree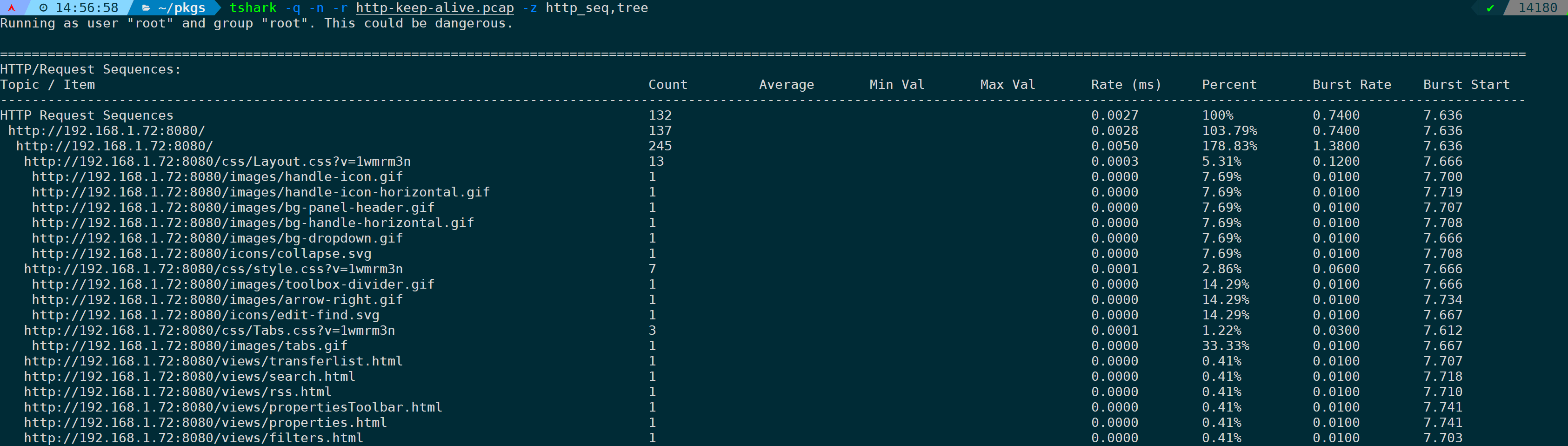
同样支持指定过滤规则:
tshark -q -n -r <filename> -z http_seq,tree,'tcp.stream==0'
15)统计计算HTTP请求和响应(http_srv,tree)
对于HTTP request,显示的值是目的端服务器IP地址和服务器主机名。对于HTTP response,显示的值是目的端服务器IP地址及状态:
tshark -q -n -r <filename> -z http_srv,tree
也支持在最后指定过滤规则,统计过滤第一条流:
tshark -q -n -r <filename> -z http_srv,tree,'tcp.stream==0'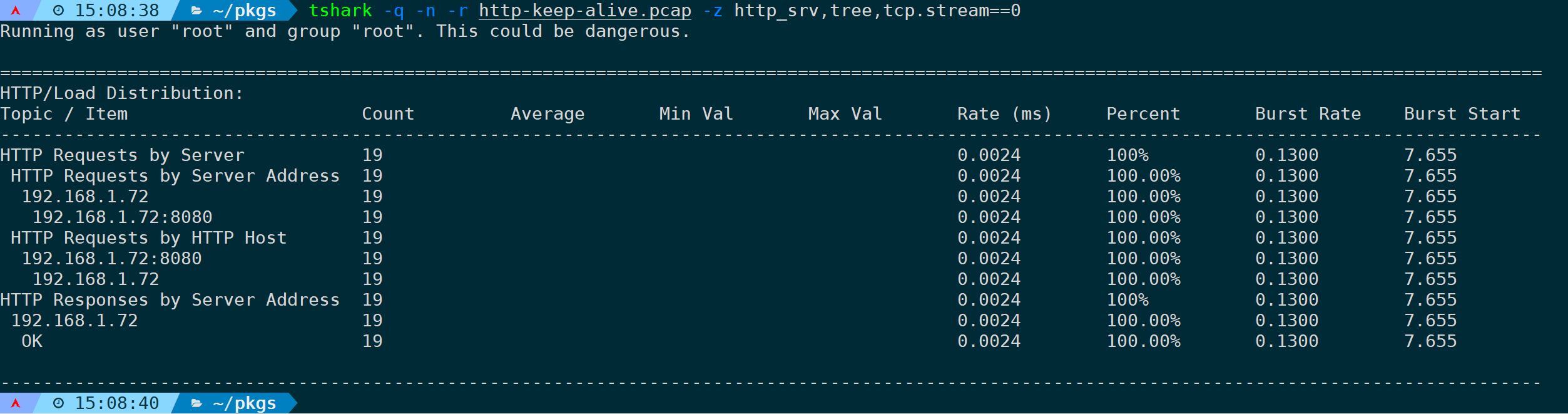
16)统计分析ICMP(icmp,srt)
计算ICMP回显请求总数、回复、丢失和丢失百分比,以及ping返回的最小、最大、平均、中值和样本标准差SRT统计信息。
tshark -q -n -r <filename> -z icmp,srt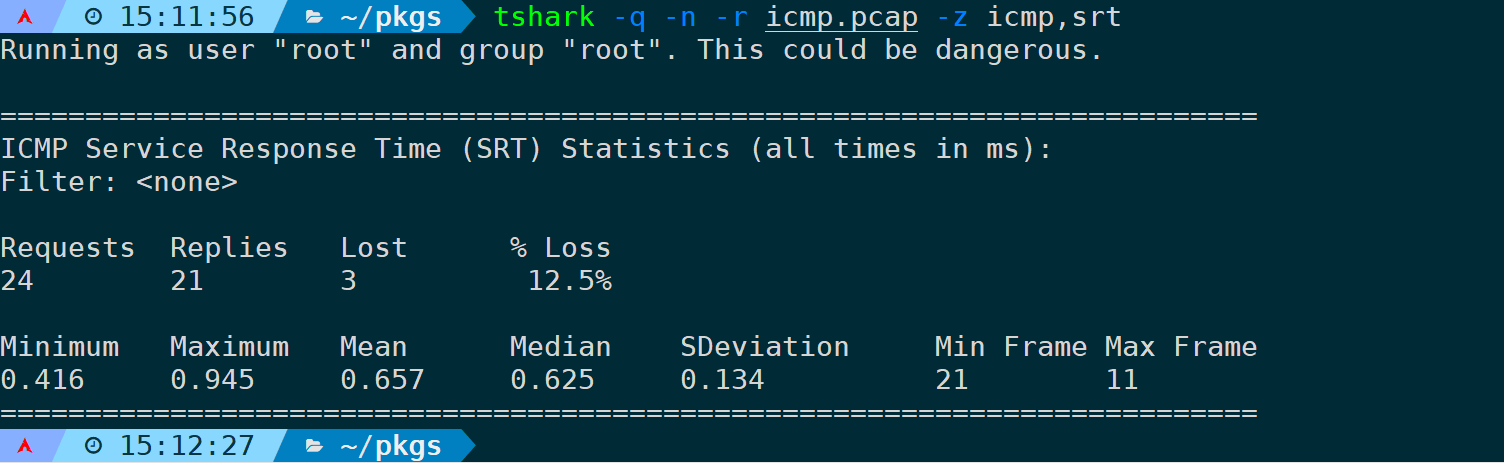
过滤某个IP地址的统计:
tshark -q -n -r <filename> -z icmp,srt,'ip.addr==xxx'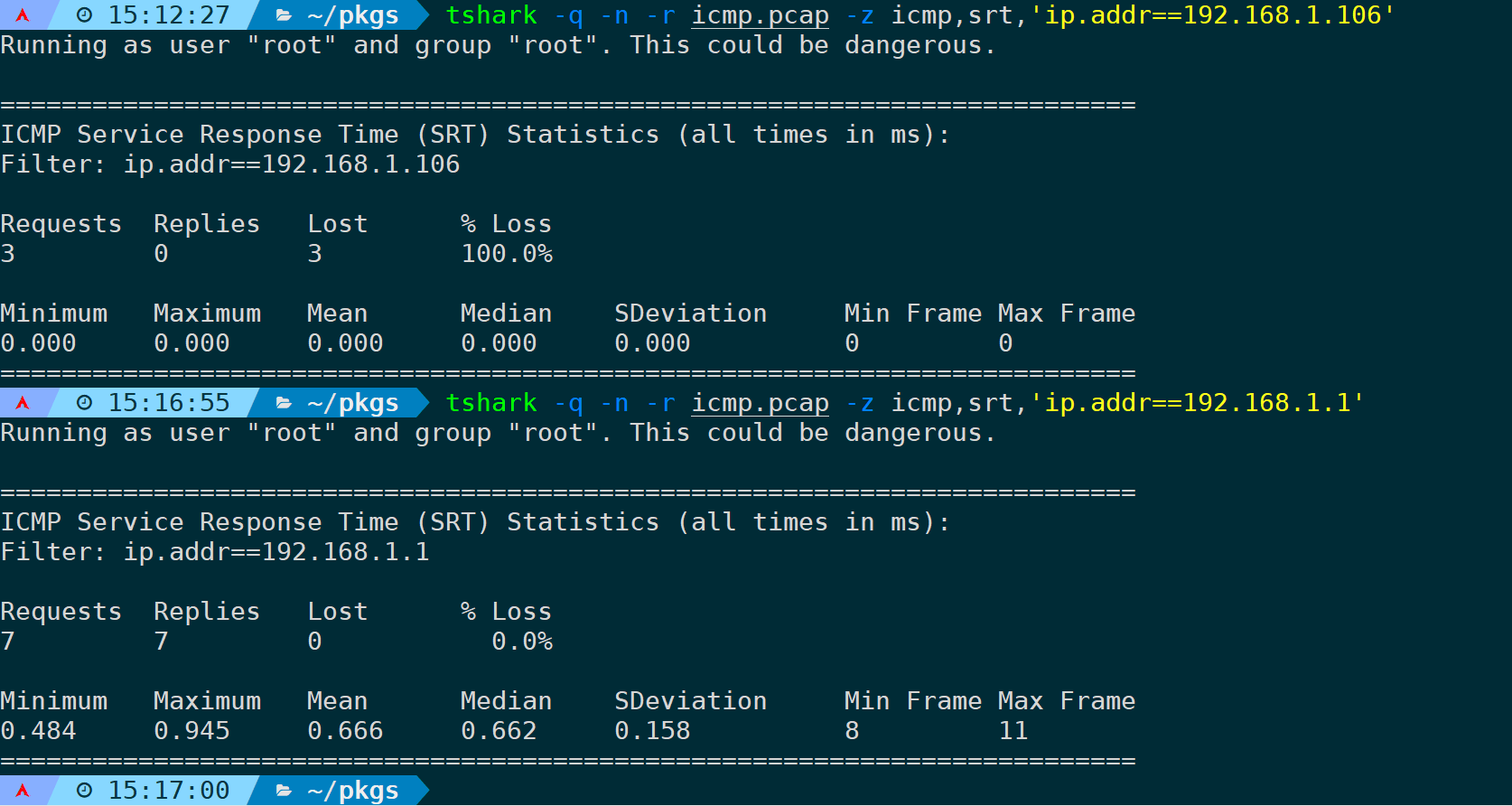
如果是V6地址,则使用icmpv6,srt。
17)统计协议层次结构及包量(io,phs)
创建协议层次结构统计信息,列出数据包数和字节数:
tshark -q -n -r <filename> -z io,phs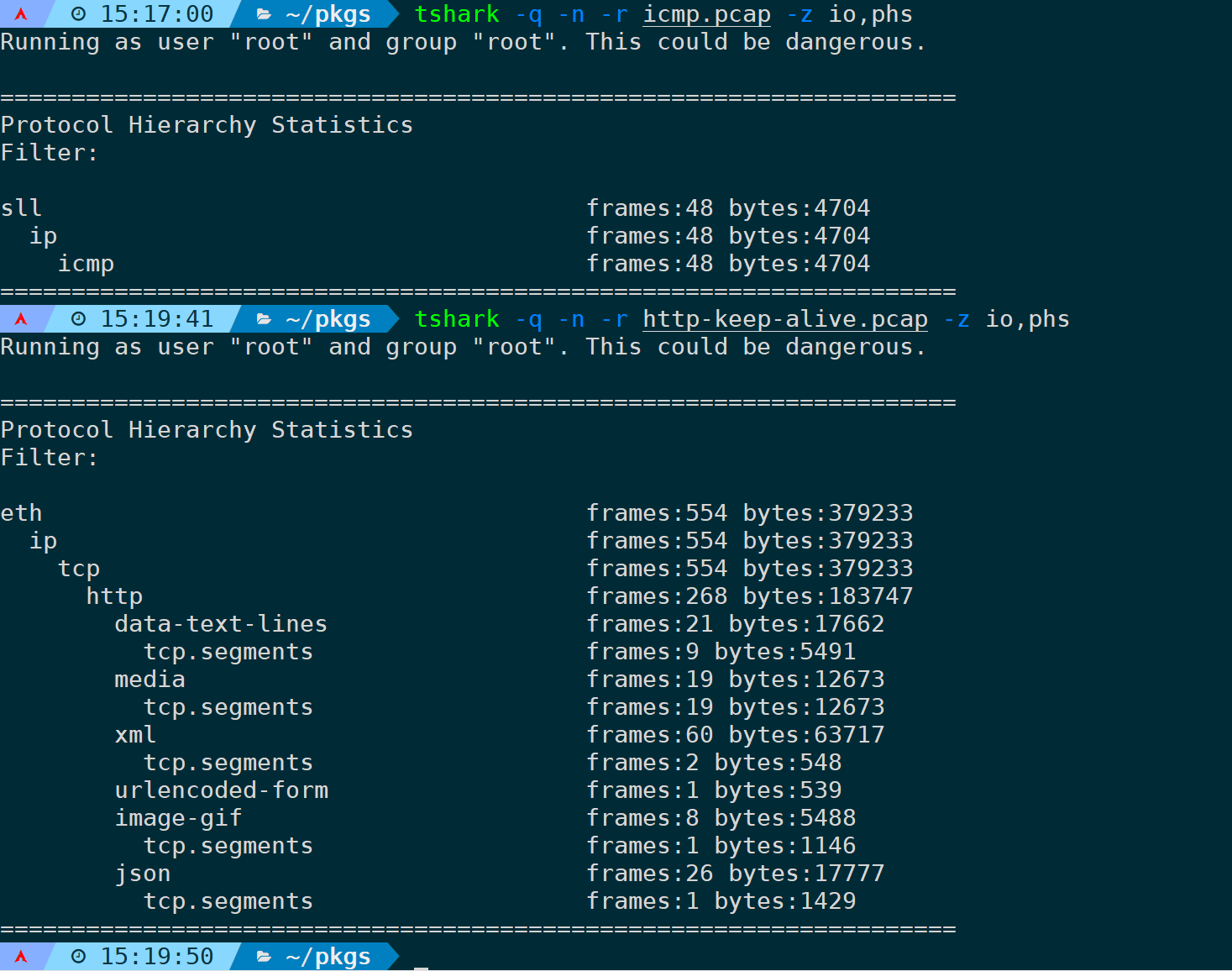
只统计第一条TCP流:
tshark -q -n -r <filename> -z io,phs,'tcp.stream==0'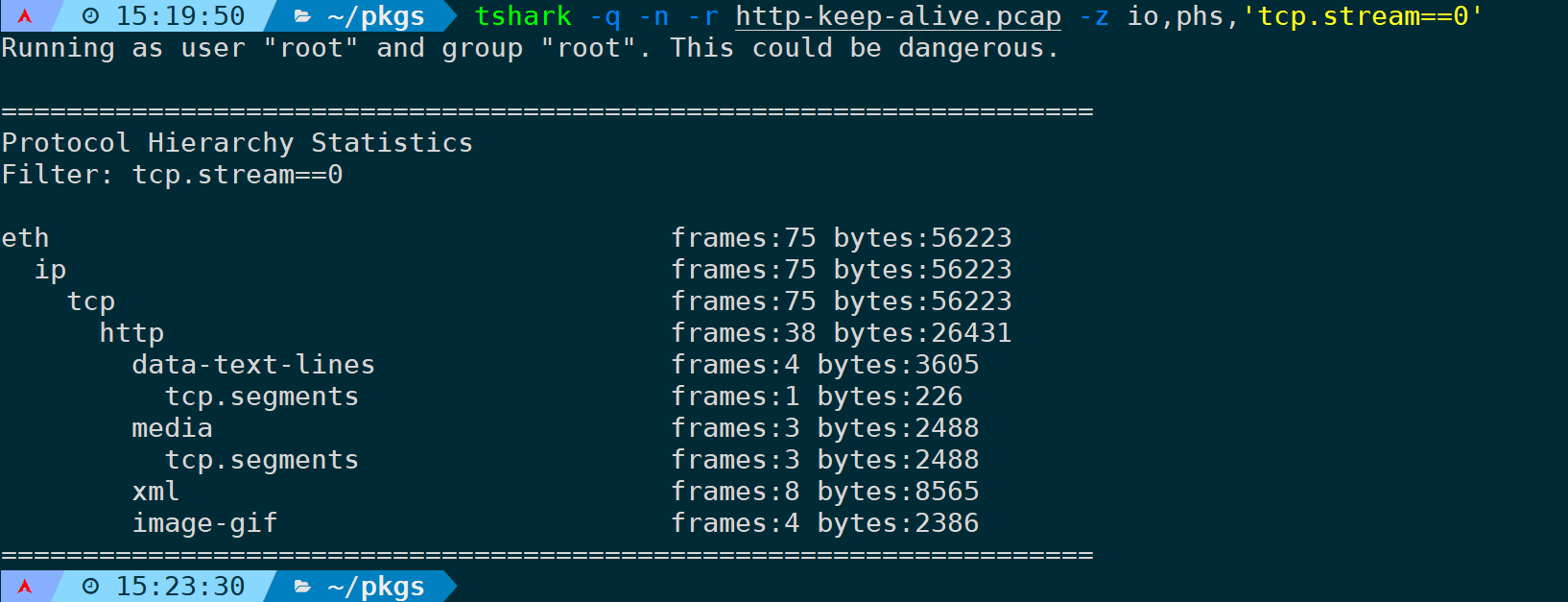
18)统计分析包量和字节大小(io,stat)
格式为:io,stat,interval[,filter]
其中io,stat是固定的,interval表示间隔时间,可以指定秒或小数秒或微秒,如果指定为0,将计算所有数据包的统计信息。
统计所有数据包的包量和字节大小:
tshark -q -n -r <filename> -z io,stat,0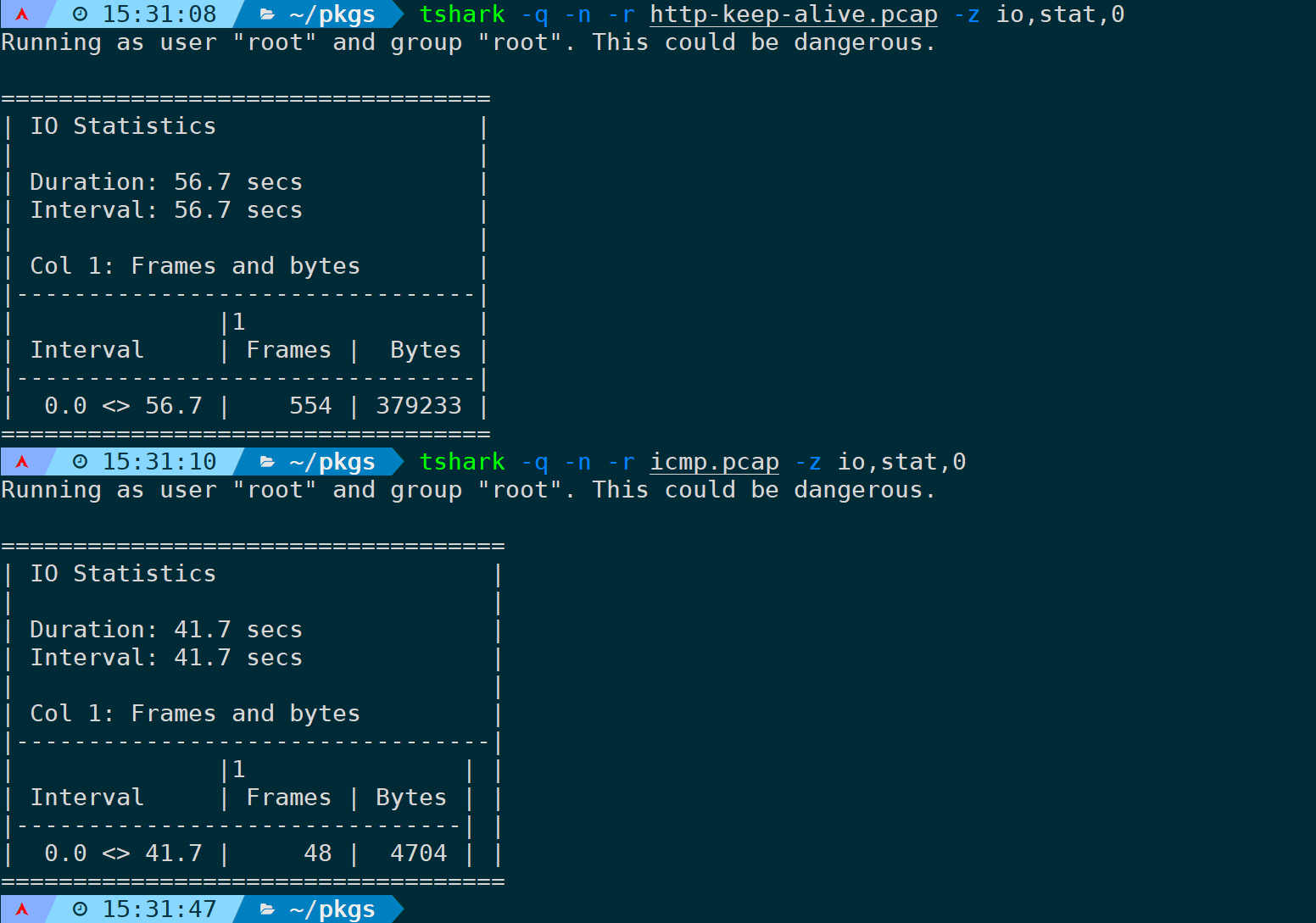
如果想指定间隔为10s统计一次,且只统计第一条TCP流则可以是:
tshark -q -n -r <filename> -z io,stat,10,'tcp.stream==0'
19)统计分析某个字段的最大最小平均值等(MAX|MIN|AVG)
依然是io,stat,但完整格式为:io,stat,interval,"COUNT|SUM|MIN|MAX|AVG|LOAD(field)filter"
io,stat是固定选项,interval表示间隔时间,其中的COUNT|SUM|MIN|MAX|AVG|LOAD都要基于过滤规则来做统计,比如:
io,stat,0,'MAX(icmp.data_time_relative)icmp.data_time_relative'统计的是icmp响应时间字段,并取最大值MAX,0表示统计所有,不分间隔。
而如果要指定某个过滤规则,在最后面加,比如只统计到某个IP的最大的ICMP响应值情况,完整的命令为:
tshark -q -n -r <filename> -z io,stat,0,'MAX(icmp.data_time_relative)icmp.data_time_relative,'ip.addr==xxx''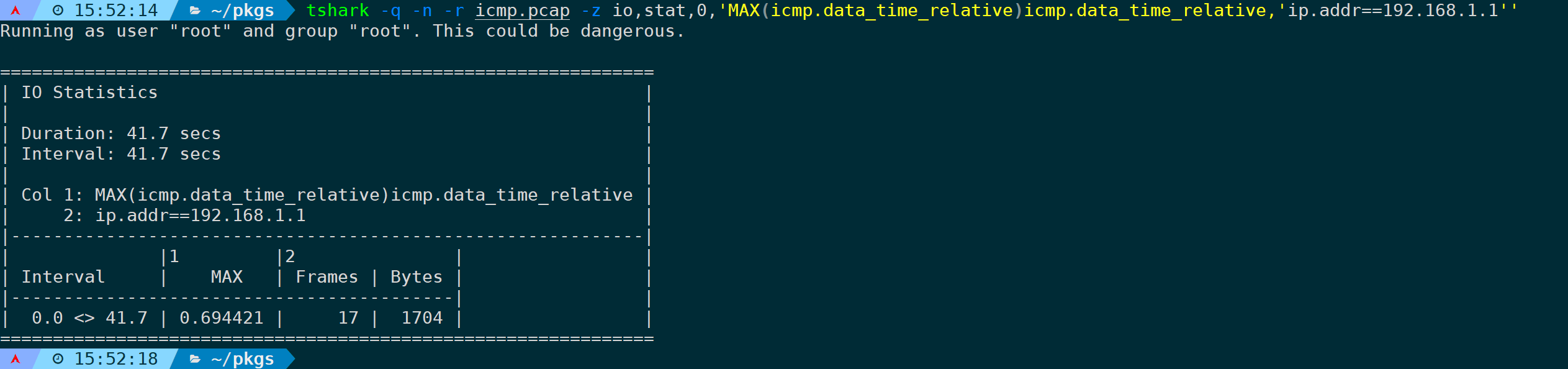
可以看到最大值为0.69s,注意单位是秒。
又或者,统计第一条TCP连接中,距离它上一个包间隔时间最长的为:
tshark -q -n -r <filename> -z io,stat,0,'MAX(tcp.time_delta)tcp.time_delta,tcp.stream==0'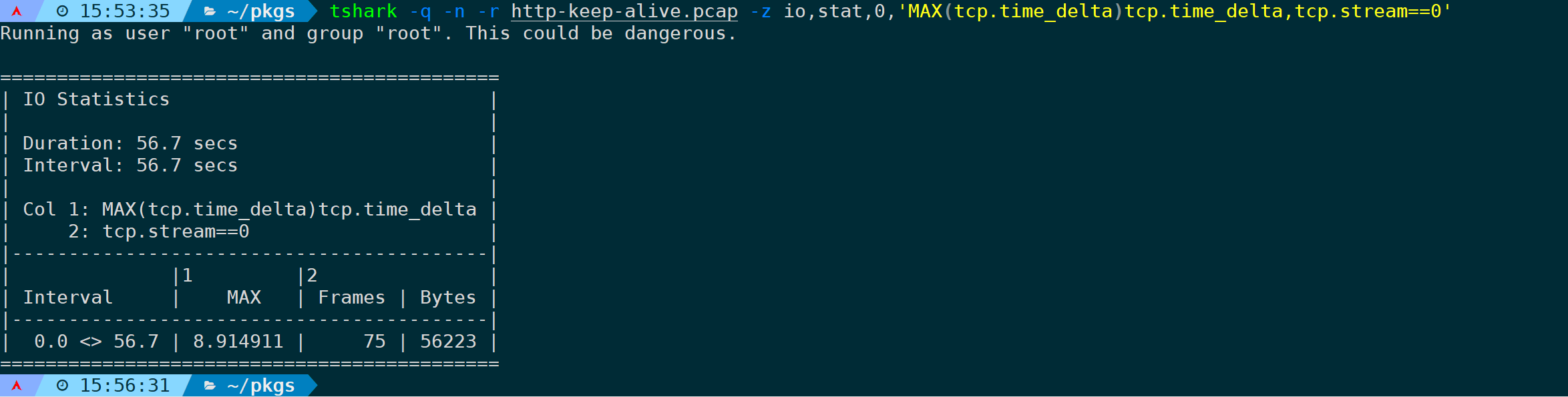
统计第一条TCP流中,HTTP响应时间的平均值和最大值,分别为:
tshark -q -n -r <filename> -z io,stat,0,'AVG(http.time)http.time,tcp.stream==0'tshark -q -n -r <filename> -z io,stat,0,'MAX(http.time)http.time,tcp.stream==0'
如果不指定过滤规则(上图是tcp.stream==0)则统计所有包含http.time字段的报文。
再或者,只统计返回了200 OK状态码的http最大响应时间:
tshark -q -n -r <filename> -z io,stat,0,'MAX(http.time)http.time and http.response.code == 200'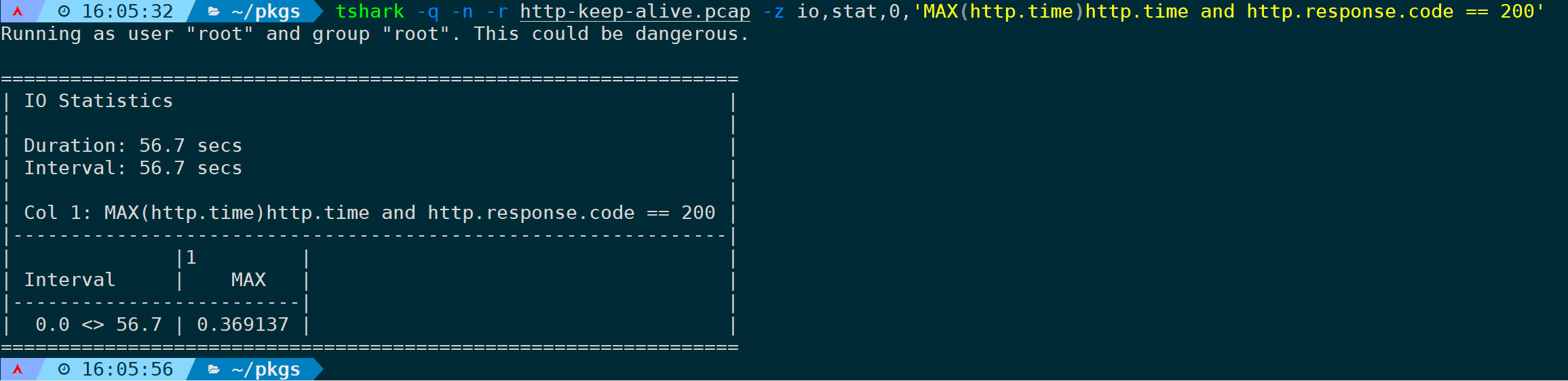
20)统计IP地址占比(ip_hosts,tree)
源和目的IP地址都会在这里展示,并显示百分比、发包速率、开始时间等:
tshark -q -n -r <filename> -z ip_hosts,tree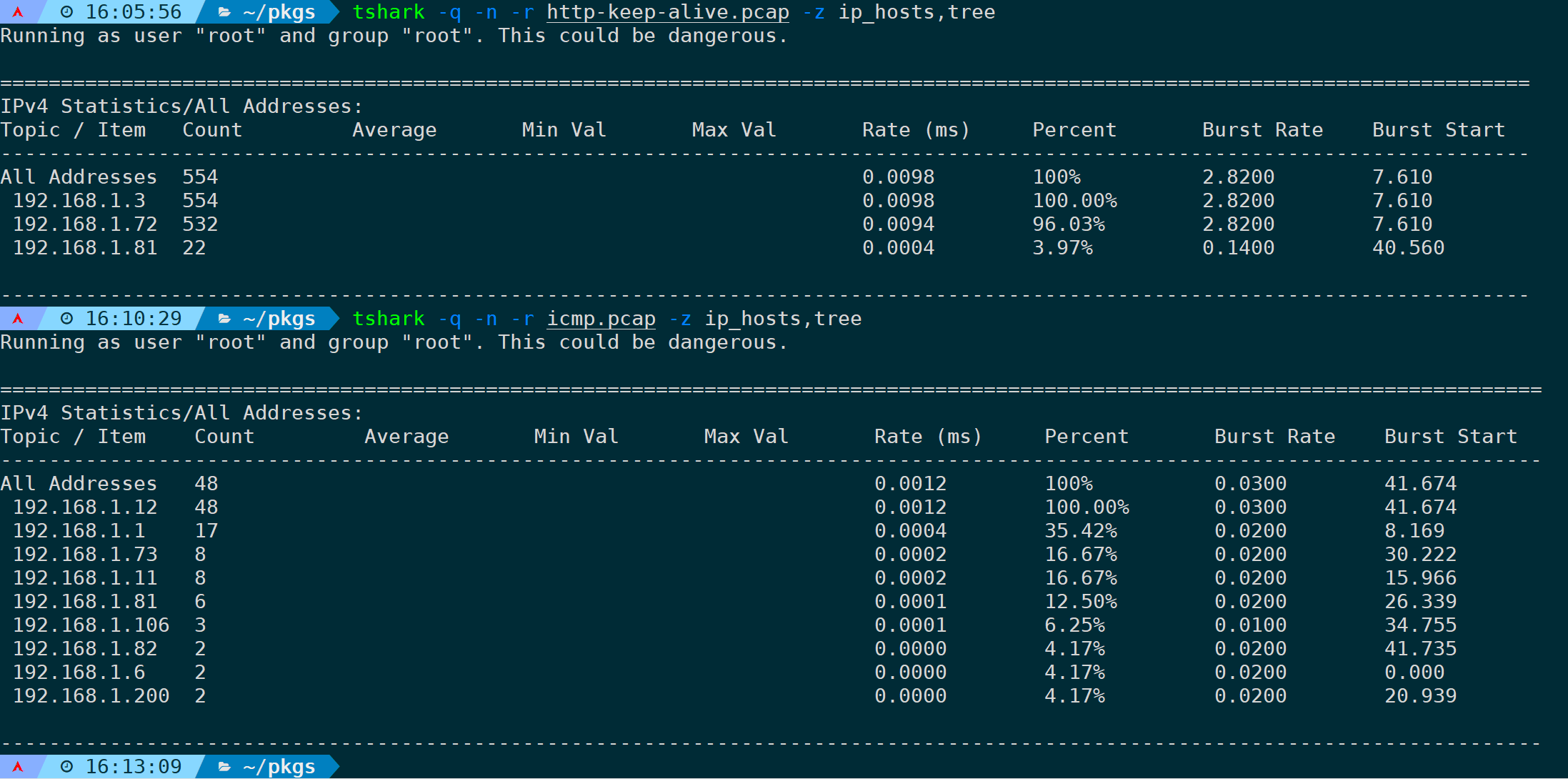
在最后指定过滤规则,比如只统计icmp序列号小于等于6的报文和只统计第一条TCP流的报文,分别是:
tshark -q -n -r <filename> -z ip_hosts,tree,'icmp.seq <= 6'tshark -q -n -r <filename> -z ip_hosts,tree,'tcp.stream==0'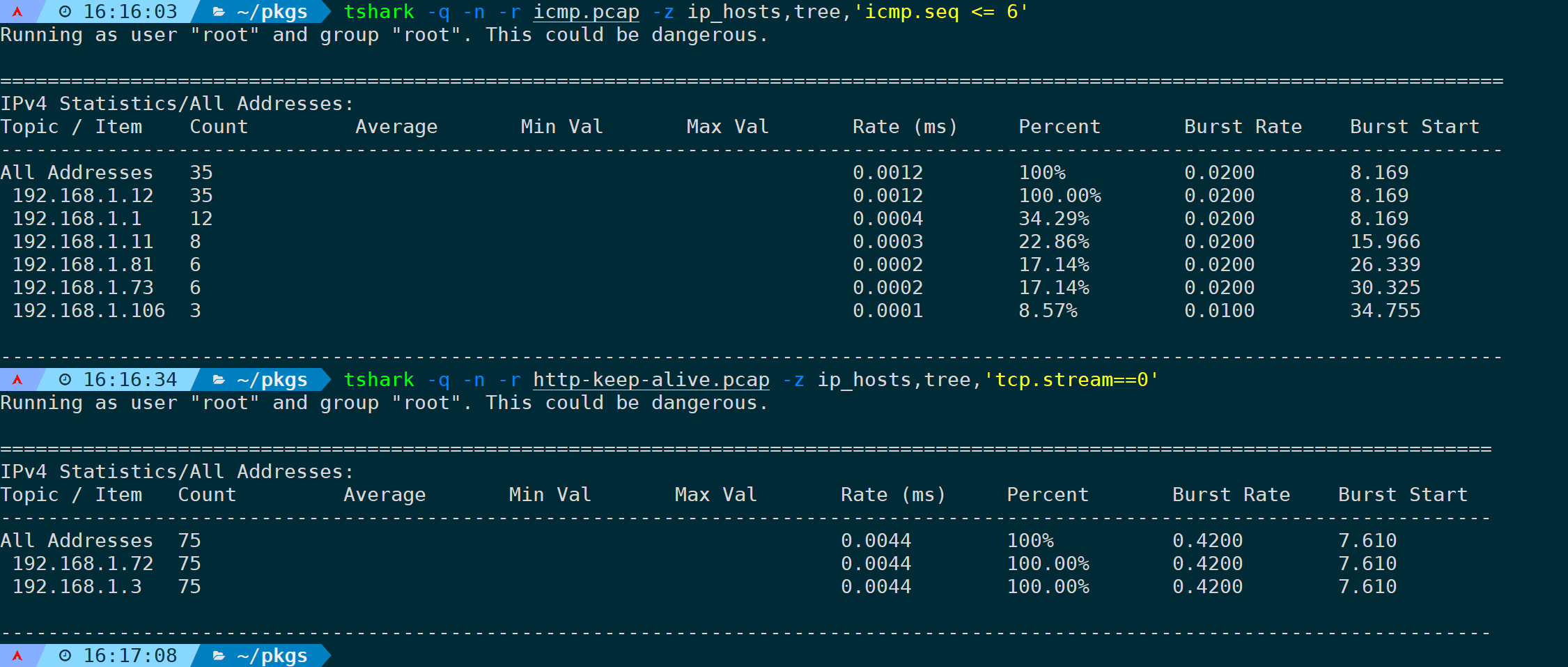
如果是IPv6地址,则使用 ipv6_hosts,tree。
21)统计源地址和目标地址占比(ip_srcdst,tree)
将源地址和目的地址区分开来,则使用ip_srcdst,tree:
tshark -q -n -r <filename> -z ip_srcdst,tree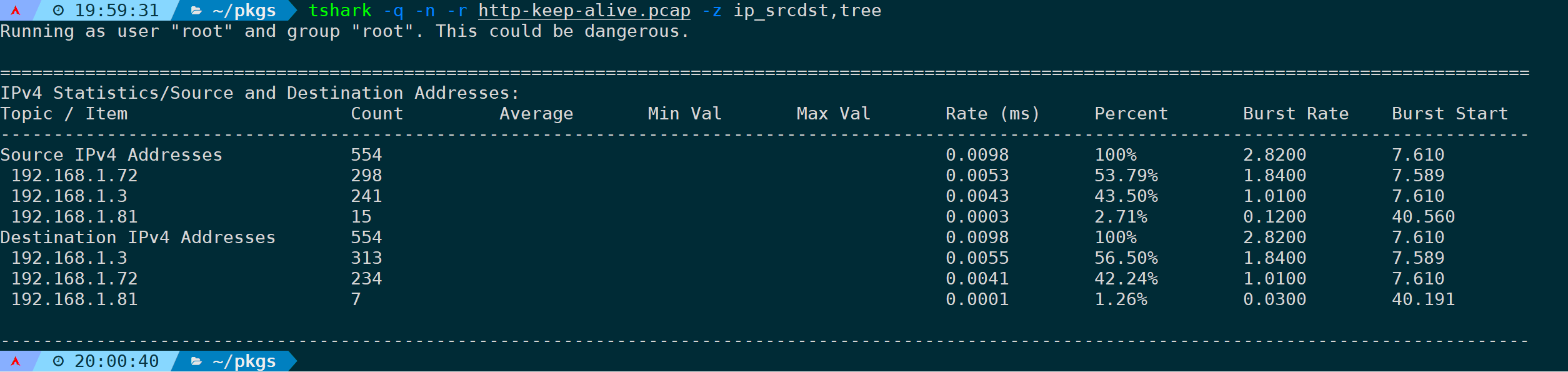
指定过滤规则,只过滤tcp端口为8080的数据:
tshark -q -n -r <filename> -z ip_srcdst,tree,'tcp.port in {8080}'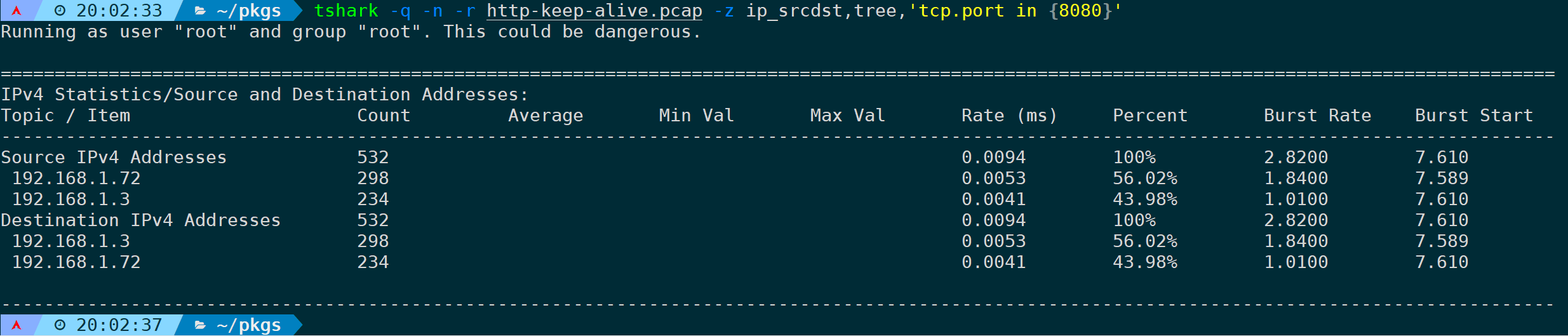
如果是IPv6地址,则使用 ip6_srcdst,tree。
11.完整展开报文(-V)
-V参数会完整展开报文的每个字段、头部信息.
比如下面这个示例,将第一次握手的请求展开:
tshark -n -r <filename> -V -Y 'tcp.flags.syn==1&&tcp.flags.ack==0&&frame.number<=5'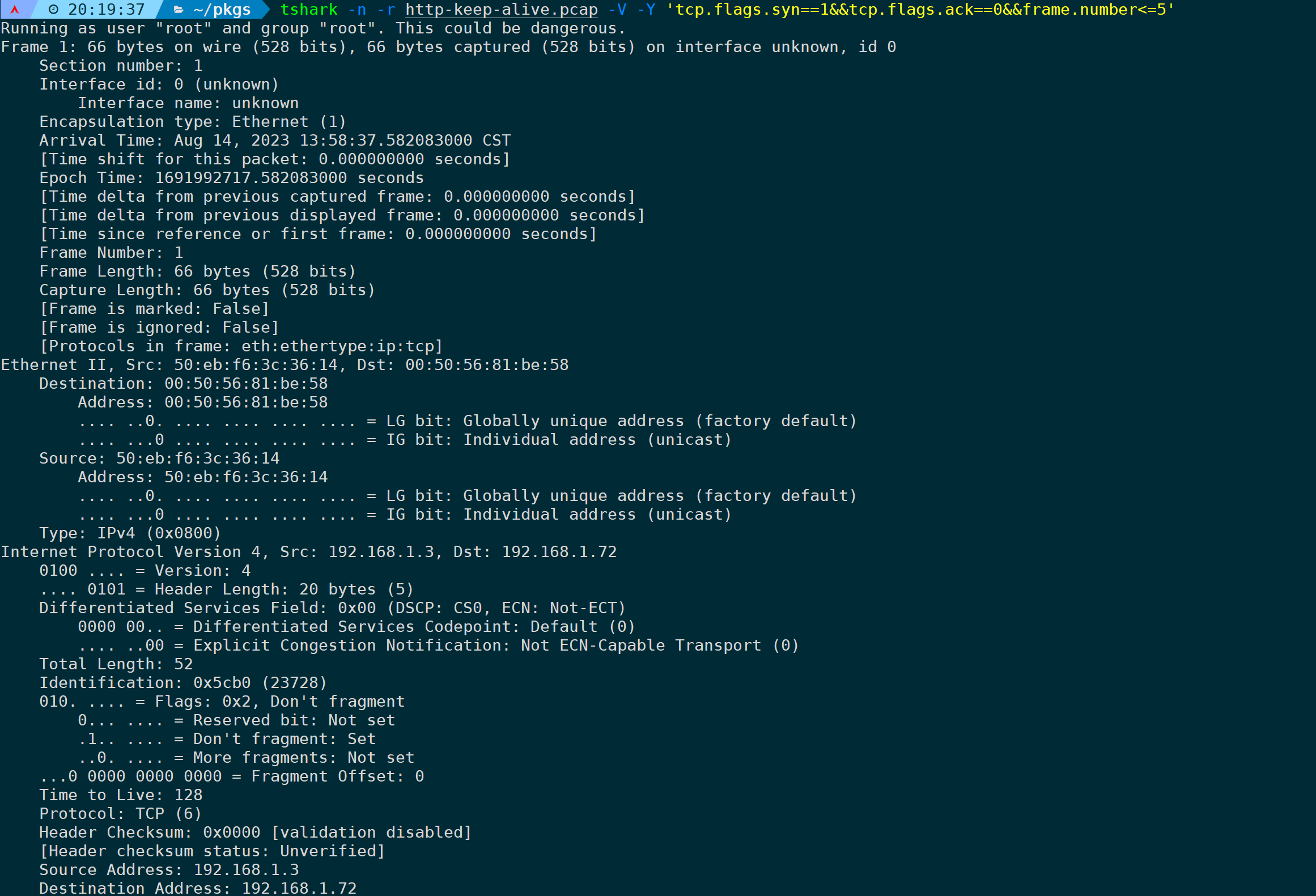
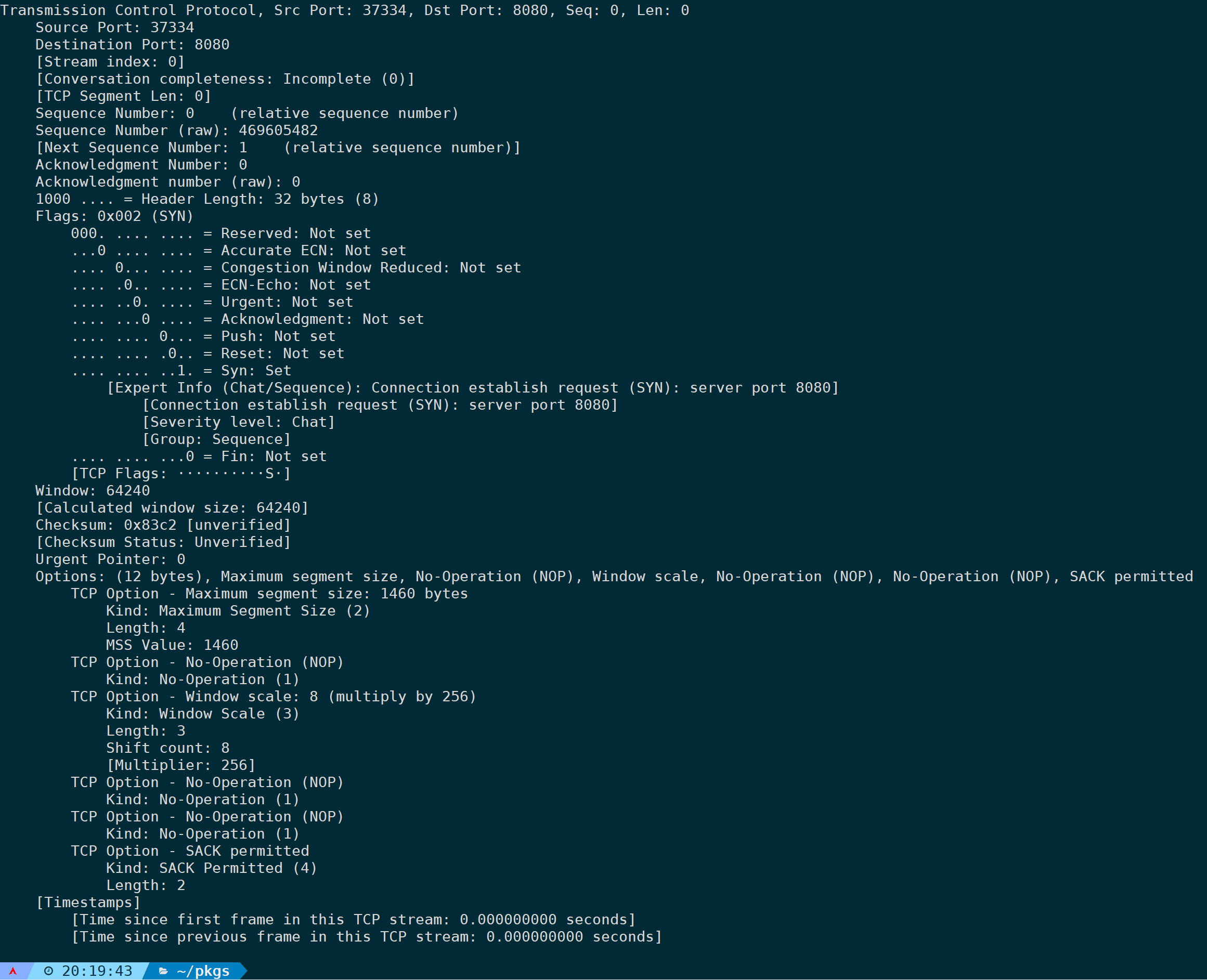
所有单个报文都能被展开,被当初数据批量过滤处理,那么就能配合Linux下的文本过滤命令,来批量拿到我们想要的字段信息。
比如通过正则来拿到我们想要的直播流URL:
tshark -n -r <filename> -Y 'http.request.method eq GET' -V | grep -Po '(?<=Full request URI:\s).*m3u8(?=])' |& sort -u
报文展开后,所有字段都能被当成普通文本处理,因此非常方便,这是图形化wireshark所做不到的。
12.保存报文(-w)
顾名思义,通过tshark处理完原始报文后,需要将过滤出来的报文保存到新的抓包文件,那么此参数就派上用场了。
比如过滤前300个报文,并且IP地址为A或B,或者目的端口为38388的HTTP报文,可以是:
tshark -n -r <filename> -Y 'frame.number<=300&&(ip.addr in {101.207.176.11,192.168.137.111}||tcp.dstport==38388)&&http'
通过-w参数来保存到一个新的抓包文件http_in_300.pcap:
tshark -n -r <filename> -Y 'frame.number<=300&&(ip.addr in {101.207.176.11,192.168.137.111}||tcp.dstport==38388)&&http' -w http_in_300.pcap
最终保存到的新抓包文件只有4.4K大小,原始文件为516MB。
四、总结
tshark作为wireshark的命令行版本,很多功能其实都是一对一息息相关的,但tshark提供了命令行能力,对于自动化脚本分析有很大的帮助,可以轻松实现自动批量化处理抓包文件,并展示分析结果。
通过过滤、分析网络数据包,它为网络管理员、安全专家和开发人员提供了深入了解网络协议的机会。无论是监控网络流量、故障排除、安全审计还是协议分析,tshark都能发挥其巨大作用。从基本的捕获和过滤到高级的Lua定制,它提供了广泛的功能和应用,适用于各种场景。
本文详细讲述了每个参数的用法及使用示例,篇幅原因无法将每种可能写进去,网络协议本身具备多样性和复杂性。通过掌握tshark其用法,再去分析协议特征,通过对协议的理解和对tshark本身的融会贯通,相信对于各大网络排障都能从中受益。







